저번 포스팅에서는 Dummy Device 에서 발생하는 데이터가 IoT Core로 게시 되고, 게시된 데이터는 IoT Rule을 통해 SQL문으로 재 정렬 되어 Amazon S3 저장소에 저장되었습니다!
오늘은 Amazon S3에 저장된 데이터를 Glue, Athena, Quicksight로 분석 및 시각화 해보는것을 진행하려고 하는데,
사실 요 부분은 IoT Core와 직접적으로 관련은 없습니다.
그렇기 떄문에 IoT Core 외 다른 서비스는 해보고싶지 않다! 하시면 이 포스팅은 패스하세요!
[IoT Core 무작정 따라하기 Step #1] IoT Core에 MQTT 데이터 보내기
안녕하세요 😊😊😊 이번 시리즈는 간단하고도 어려운 Amazon IoT Core 시간입니다. 설명도 중간중간 진행하겠지만, 가장 기본적으로는 Step By Step으로 따라하면 무조건 성공할 수 있도록 단계별로
1mini2.tistory.com
[IoT Core 무작정 따라하기 #2] IoT Core로 들어온 데이터 모니터링
안녕하세요 🤗 이전 포스팅을 통해 가짜 Device에서 MQTT로 IoT Core 로 보내는것까지 진행을 했습니다. [IoT Core 무작정 따라하기 #1] IoT Core에 MQTT 데이터 보내기 안녕하세요 😊😊😊 이번 시리즈는
1mini2.tistory.com
한번 진행해봅시다.!!! 고고!!👍🏻👍🏻👍🏻
[아키텍쳐]

[목차]
1. Glue 서비스로 S3에 저장된 데이터 스키마 파악
2. Athena 로 S3의 데이터 쿼리
3. QuickSight로 데이터 시각화
[실습시작]
1. Glue 서비스로 S3에 저장된 데이터 스키마 파악
AWS Glue Crawler는 데이터 스토어(S3)에 저장되어있는 파일(json)을 읽고, 스키마를 파악하여 Glue 데이터베이스에 데이터 스키마를 저장합니다. 😁 (하둡에코시스템의 Hive metastore의 역할이라고 보시면 됩니다.👍🏻)
크롤러를 사용해봅시다.!!!
AWS Glue 콘솔에 접속합니다.
왼쪽 네비게이션바의 "크롤러"를 클릭합니다.
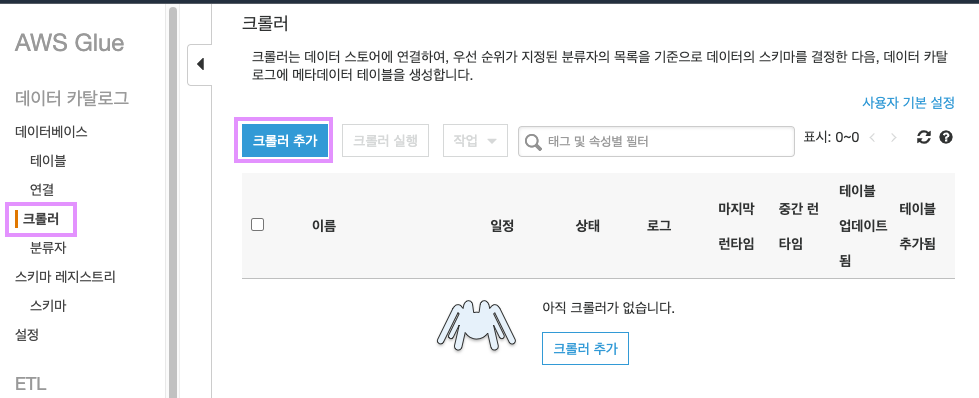
크롤러의 이름을 입력하고 다음을 클릭합니다.
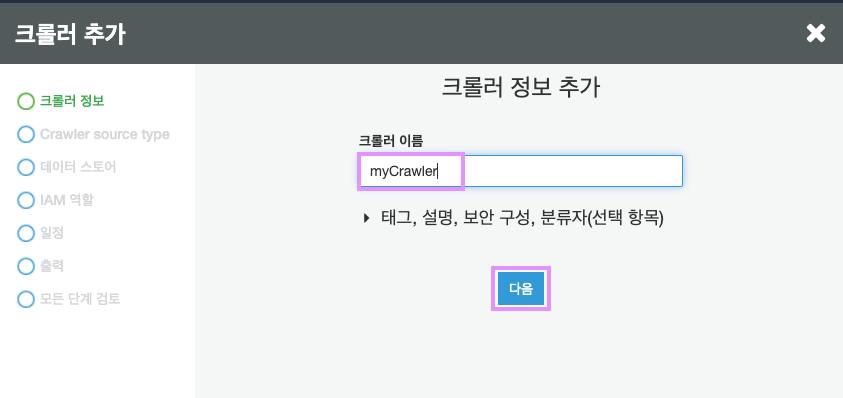
이 단계에서는 아무것도 건들지 않고 지나갑시다!
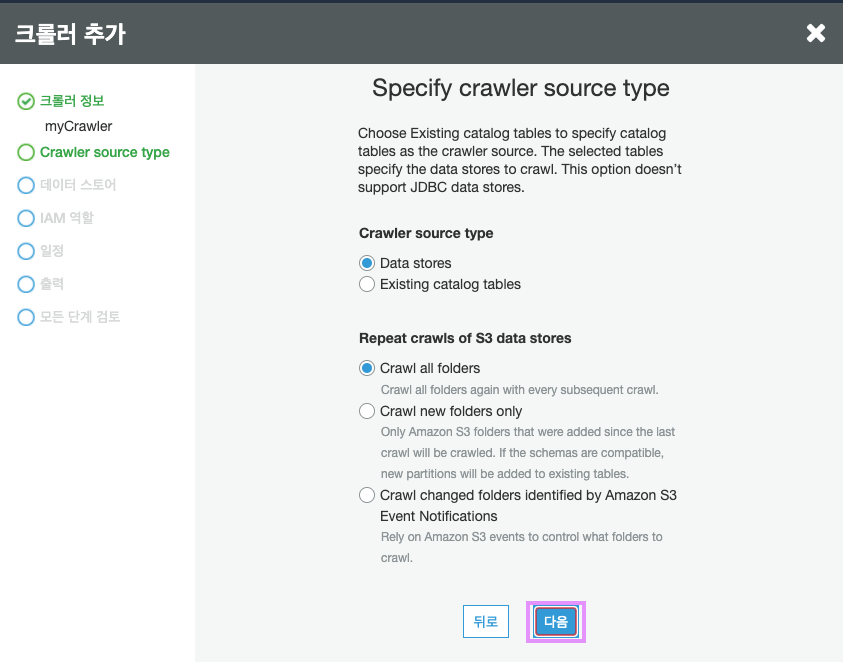
데이터 스토어를 선택합니다.
우리는 Amazon S3를 데이터 스토어로 사용하고 있습니다. 아래 포함경로에서 S3 버킷 을 선택하고 다음을 클릭합니다.
(폴더아이콘을 클릭하면 마우스로 선택 하능합니다!)
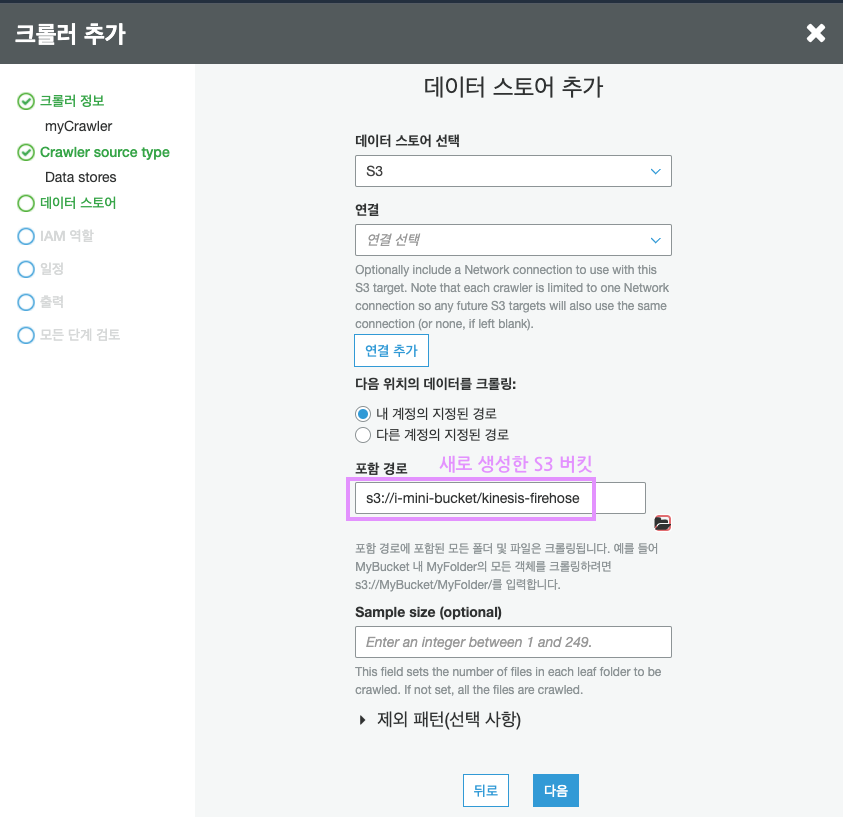
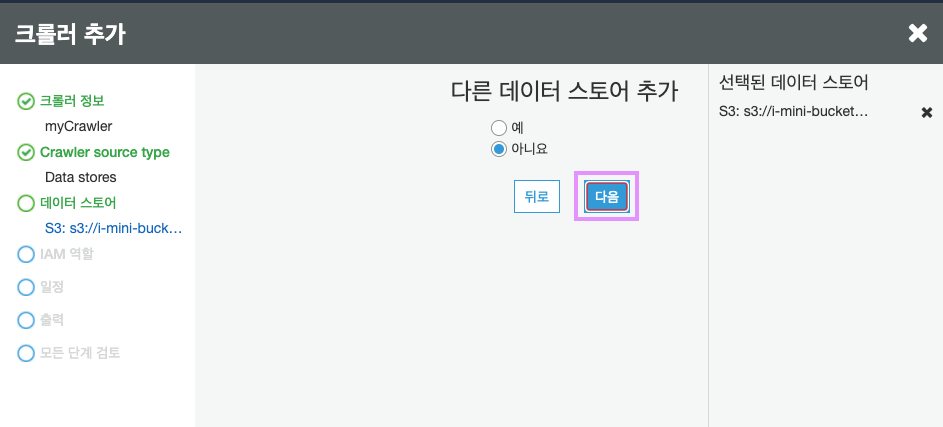
다른 데이터 스토어를 더 추가하지 않기때문에, 그대로 두고 다음을 클릭합시다.
크롤러에게 할당할 IAM 역할을 생성합니다.
크롤러는 Amazon S3를 읽을 수 있는 권한이 필요하며, "IAM 역할 생성" 시 필요한 권한이 들어가있는 IAM 역할을 자동으로 생성해줍니다.

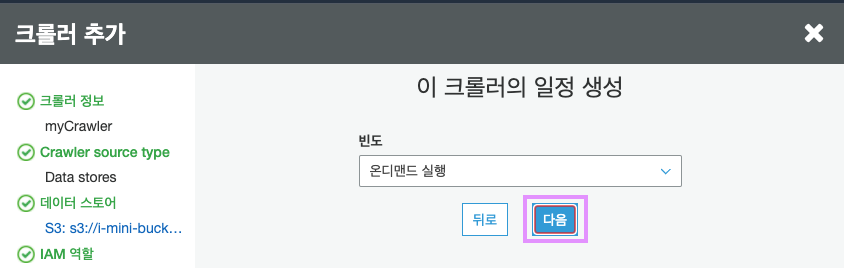
크롤러의 일정을 선택합니다.
저는 필요할때만 실행할 예정이기때문에 온디멘드실행을 선택했습니다.
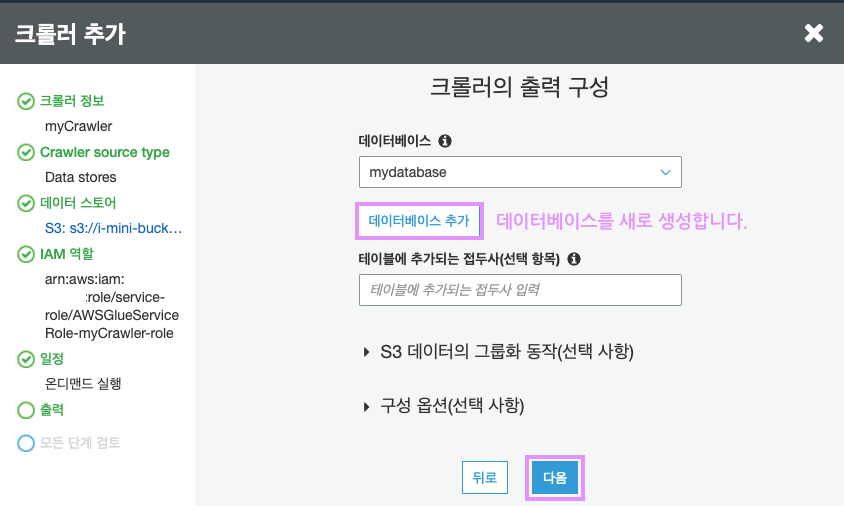
크롤링 된 데이터의 스키마를, 어떤 이름으로 저장할지 지정하는 단계입니다.
데이터베이스 추가를 클릭하여 새로 생성한 후, 다음을 클릭합니다.
크롤러 설정이 잘 들어가있는지 확인한 후 "마침"을 클릭합니다.
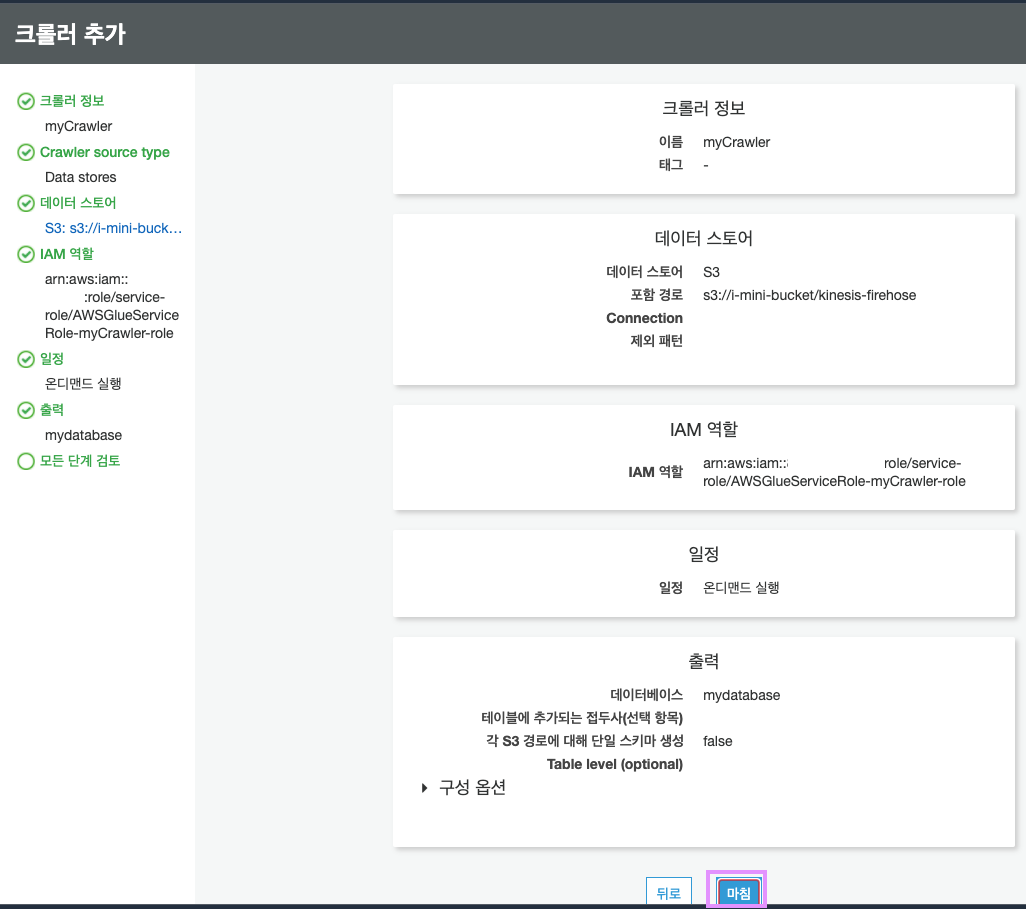
방금 생성된 크롤러를 클릭하고, 위쪽의 "크롤러 실행" 버튼을 클릭합니다.
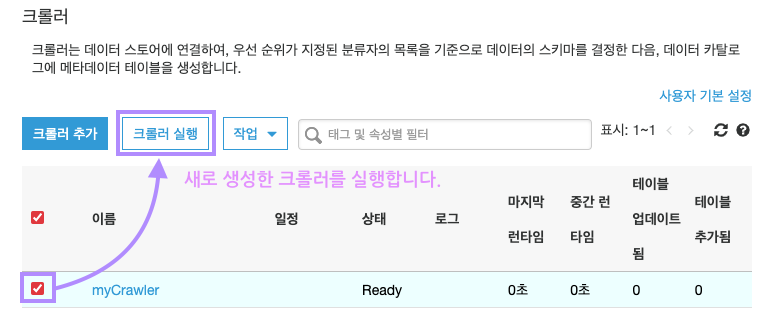
크롤러 실행이 모두 끝나면, 새로운 데이터테이블이 생성됩니다. 확인해보겠습니다!
왼쪽 네비게이션 바에서 "테이블"을 클릭하고 방금 새로 생성된 테이블을 클릭합니다.
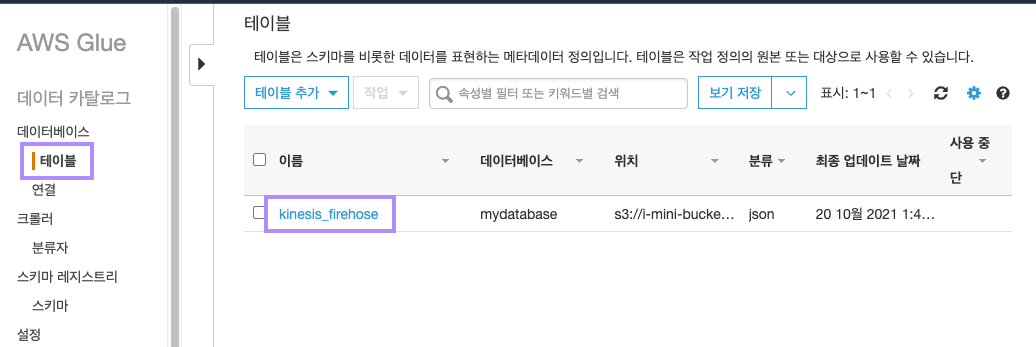
이 테이블에는 S3에 저장된 데이터가 어떤 형식으로 저장되어있는지를 정의해 놓았으며, 이를 우리는 일반적으로 스키마라고 하죠. 😊
즉, AWS Glue Crawler를 이용해서 S3에 저장되어있는 파일 데이터의 스키마 (메티데이터)를 가져왔습니다.
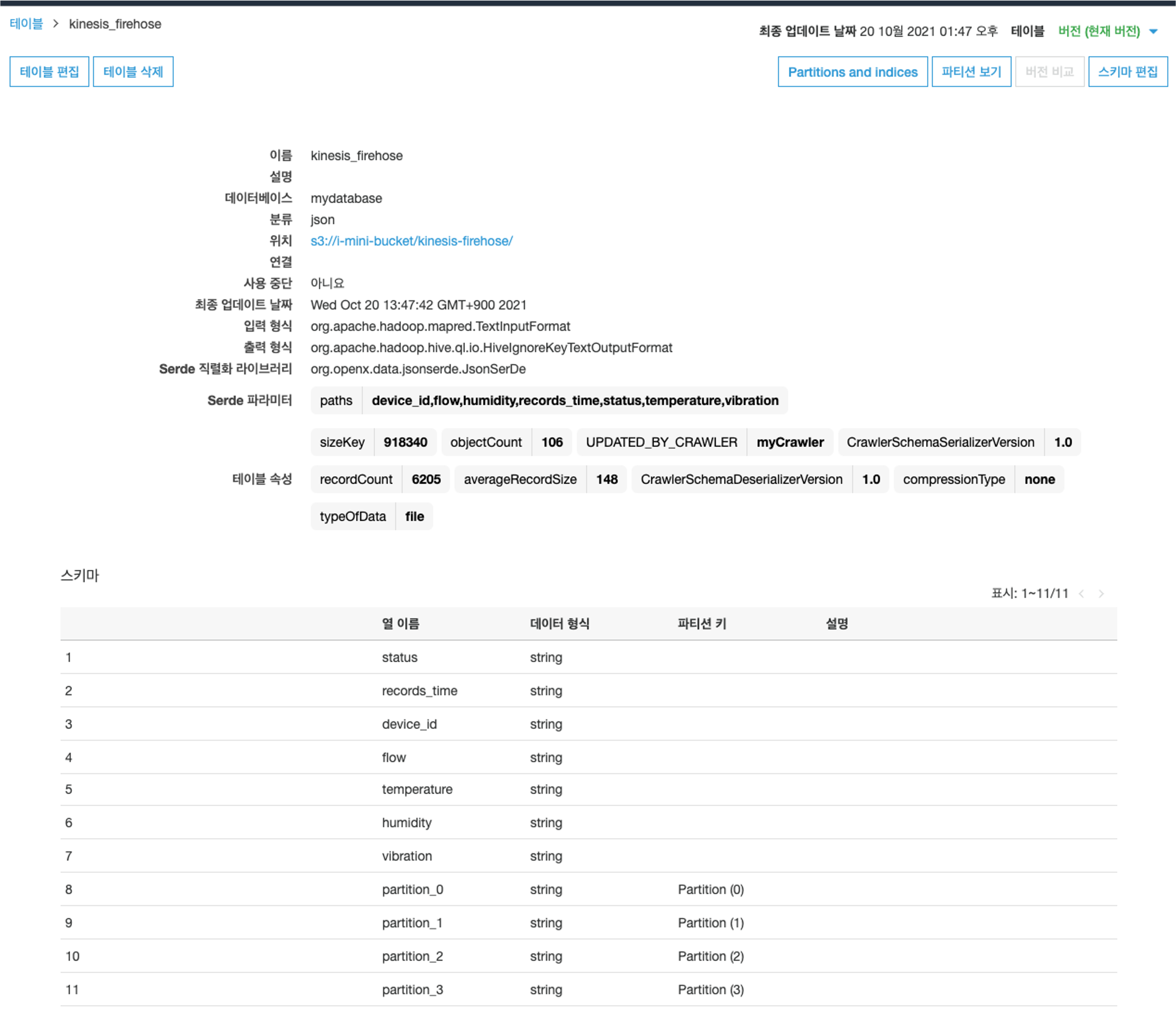
이제 이 데이터 스키마를 이용해서 실제 데이터를 쿼리해봅시다!
2. Athena 로 S3의 데이터 쿼리
AWS Athena 콘솔에 접속합니다.
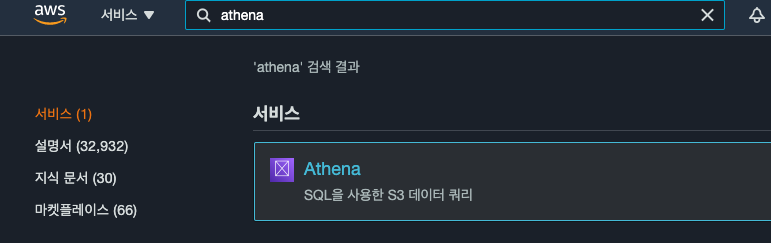
Athena를 처음 실행하는 경우, 작업 그룹에 쿼리 결과를 저장할 Amazon S3 위치를 지정해줘야 합니다.
새로운 Amazon S3 버킷을 만들어서 Athena 쿼리 결과가 저장 될 수 있도록 합시다!
(새로운 S3 버킷 만드는법은 아래 더보기를 클릭하세요!)
Amazon S3 콘솔에 접속합니다.

S3 콘솔에서 오른쪽, 버킷만들기를 클릭합니다.
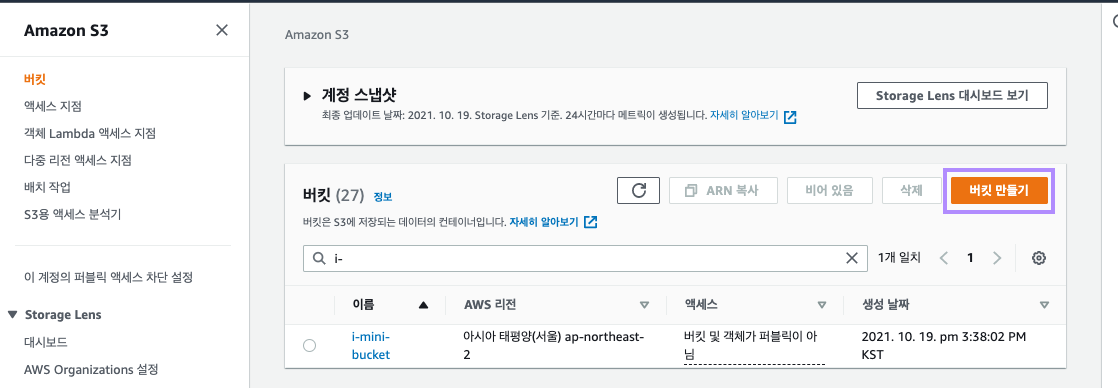
이름만 작성하고, 아래 스크롤 다운 하여 "버킷만들기"를 클릭하여 새로운 버킷을 생성합니다.
아래 스크린샷 처럼 i-mini-athena 라는 이름의 버킷을 새로 생성했습니다!
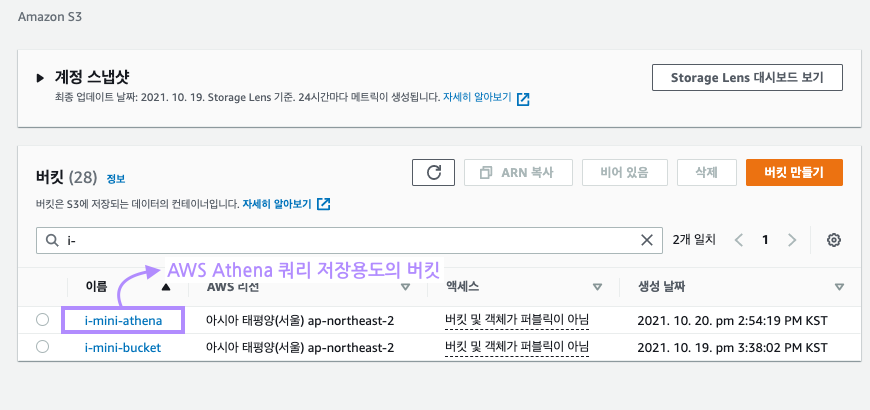
이제 다시 Athena로 돌아갑시다!!!!
Athena 콘솔 접속 후 상단 "작업그룹: primary" 탭을 클릭합니다.
primary 작업 그룹을 선택 후 세부정보 보기를 클릭합니다.
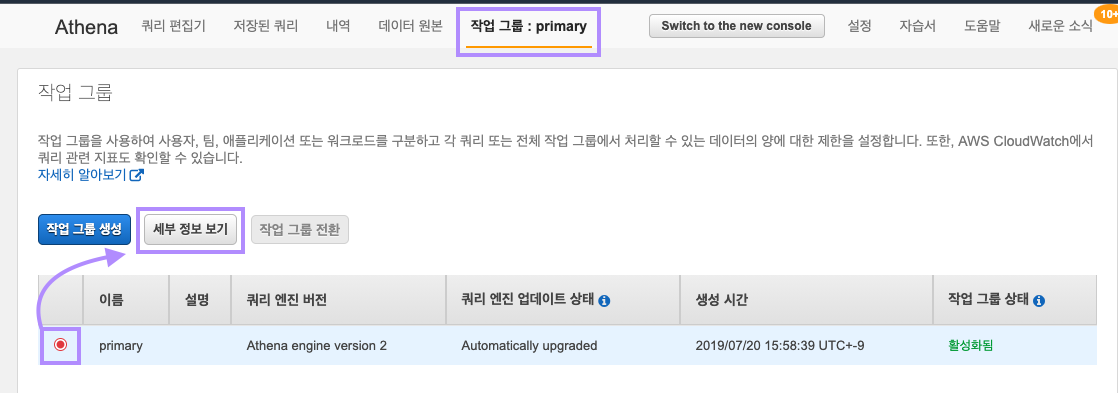
"작업그룹편집"을 클릭합니다.
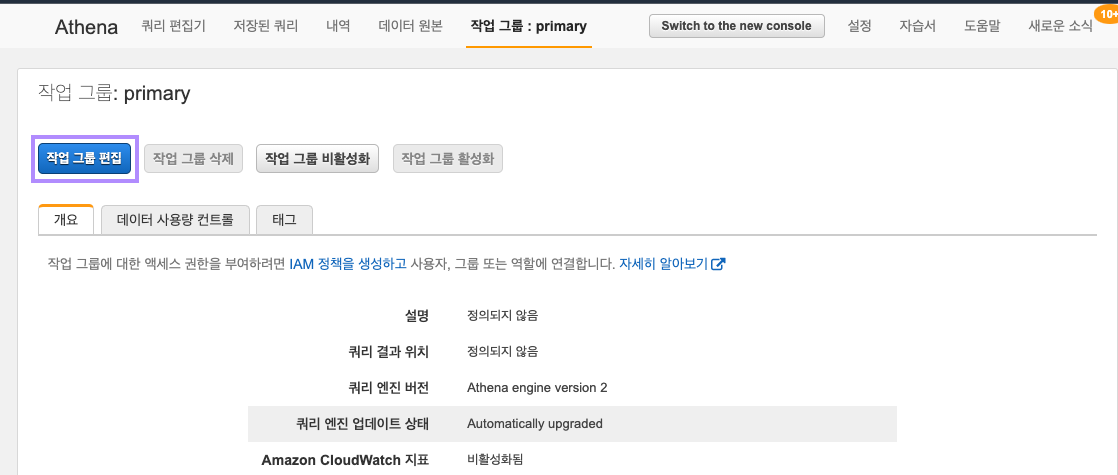
작업 그룹 편집 창에서 쿼리결과 위치만 지정하고, 나머지는 그대로 둔 후 스크롤 다운하여 "저장" 을 클릭합니다.
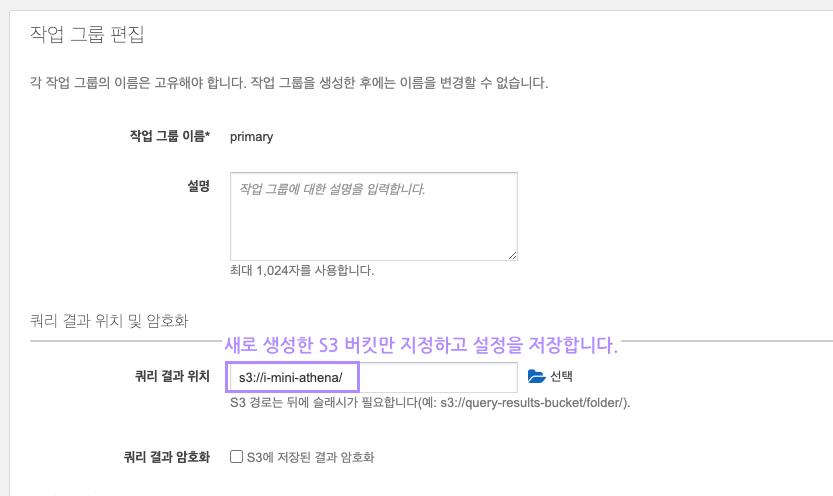
작업 그룹 확인 시 아래 캡쳐사진과 같이 쿼리 결과 위치가 잘 지정되어있는지 확인합니다.
이제 진짜로 데이터를 쿼리해봅시다.
Athena 콘솔 상단 탭에서 "쿼리편집기"를 클릭합니다.
테이블 목록에서 Glue 크롤러로 생성한 kinesis_firehose 테이블이 있습니다! 테이블 미리보기를 통해 간단한 Select 문을 실행해보고, 결과를 확인합니다.
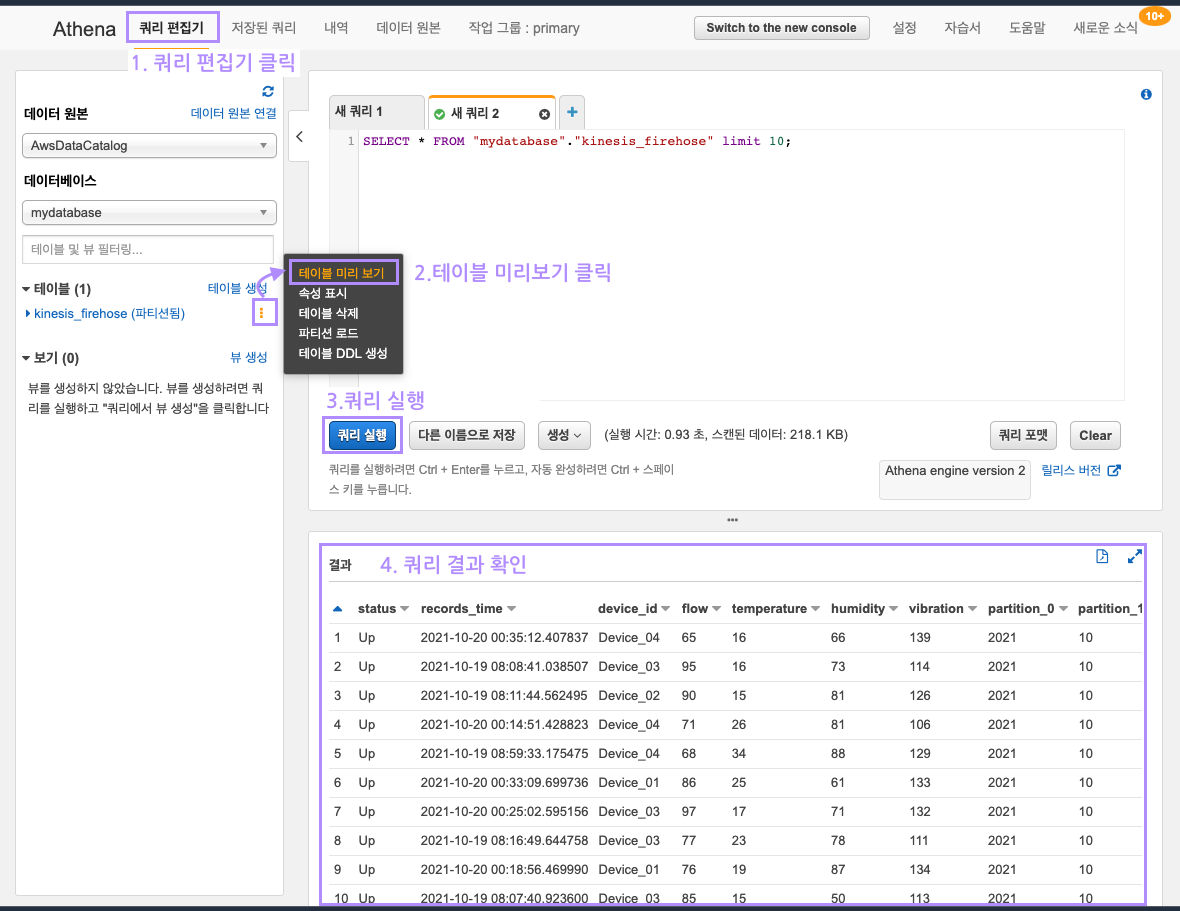
이렇게 Glue + Athena 를 통해 파일 데이터를 마치 관계형 데이터베이스처럼 사용할 수 있게 되었습니다.
원본 데이터에서 원하는 결과를 위해 쿼리문을 작성하고, 뷰를 생성할 수도 있습니다!
이제, QuickSight로 데이터를 시각화 해봅시다.!!!
3. QuickSight로 데이터 시각화
AWS QuickSight 콘솔에 접속합니다.
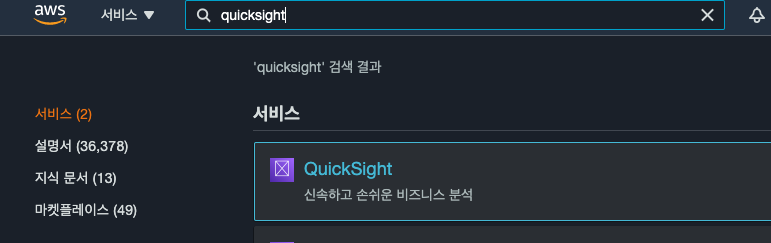
QuickSight를 처음 사용할땐, QuickSight 서비스에 가입해야 합니다. 가입해봅시다!
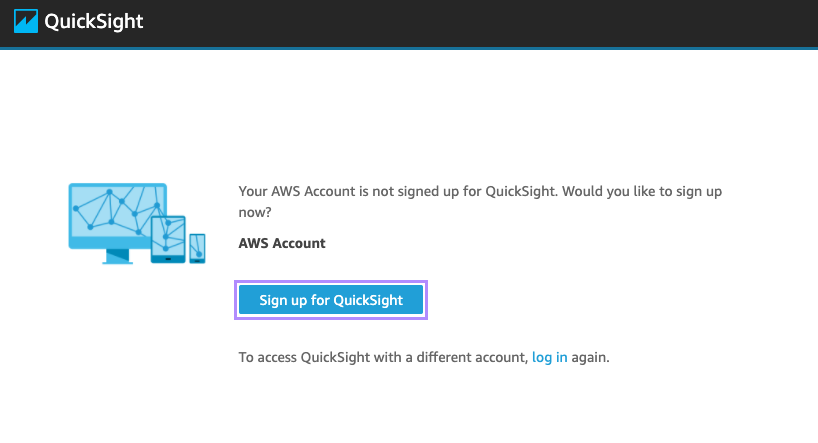
첫 페이지가 엔터프라이즈 버전이니, 저는 상단에 "Standard"를 클릭해서, 스탠다드 에디션을 사용하겠습니다.
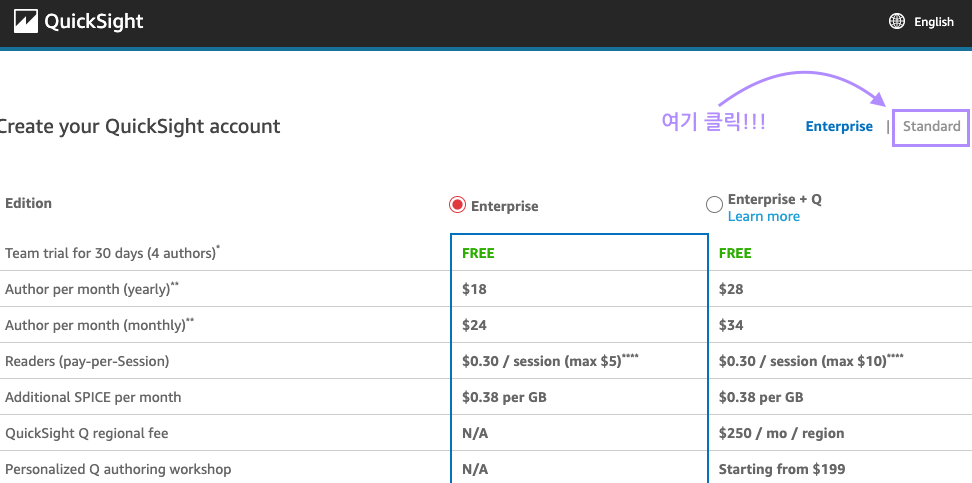
QuickSight의 리전 (저는 서울입니다😙), 사용할 계정 이름과 확인 가능한 이메일을 작성합니다.
아래에 QuickSight access to AWS service 부분에서 Amazon S3와 Athena를 클릭합니다.
각 서비스를 클릭하면 팝업이 나올텐데, 위에서 만들었던 Amazon S3 버킷 읽기, 쓰기 모두 허용해주시면 됩니다!
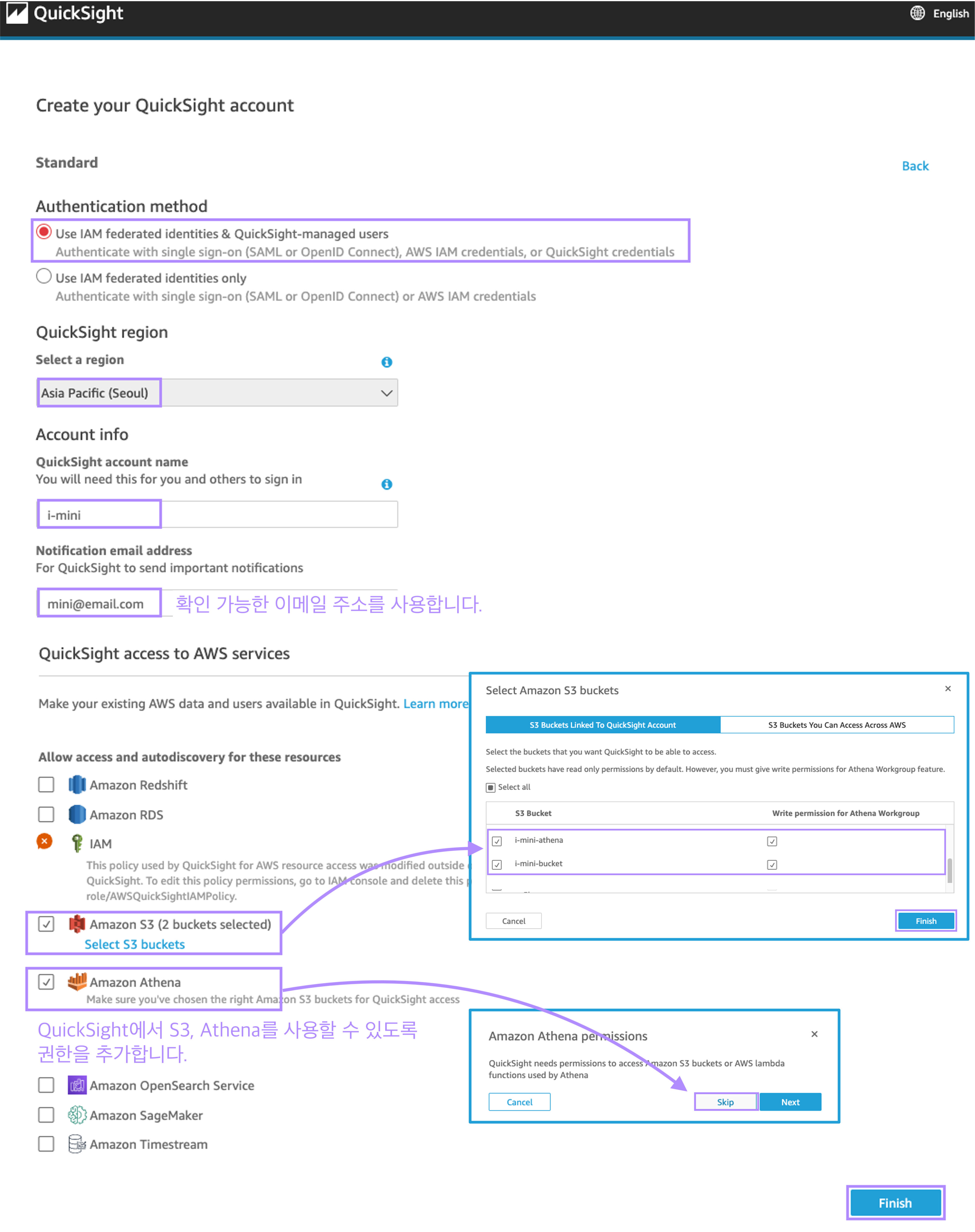
드디어! 가입 절치가 끝났습니다. 이제 진짜로 그래프를 만들어 보러 갑시다!

먼저, Quicksight로 데이터를 로딩해와야합니다.
왼쪽 네비게이션 바에서 "Datasets" 클릭 후, 오른쪽 상단에 "New dataset"을 선택합니다!
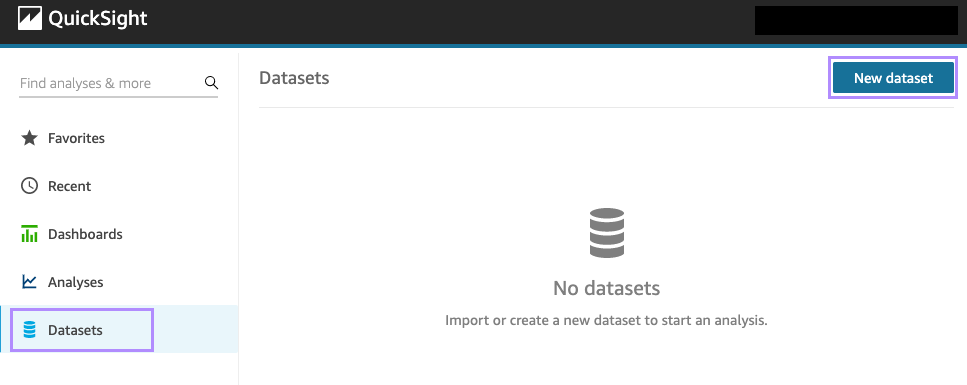
데이터를 어디서 불러올지 선택하는 단계입니다. Athena를 선택합니다!
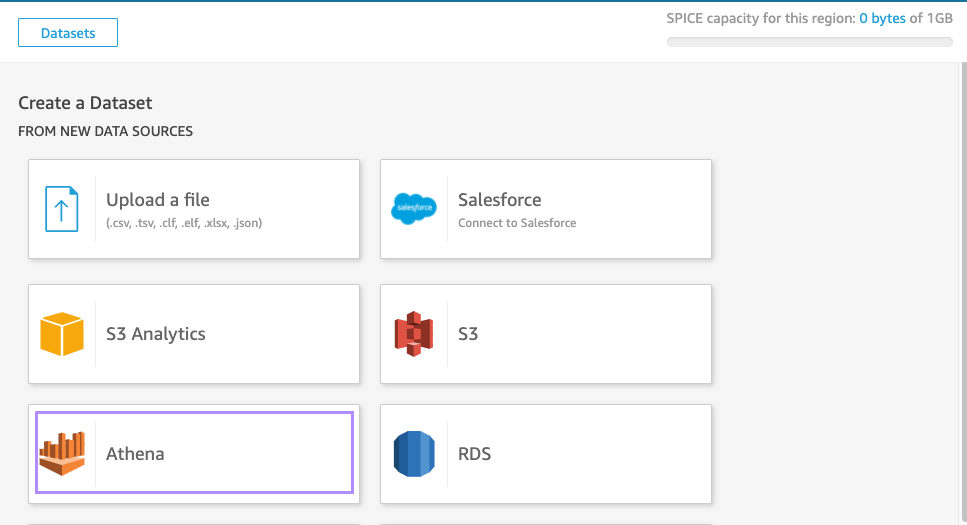
Athena 테이블을 연결합니다.
데이터 소스 이름을 작성한 후 "Create data source"를 클릭합니다. 다음 팝업창에서 Glue에서 생성했던 테이블을 선택하고 "Select"을 클릭합니다.
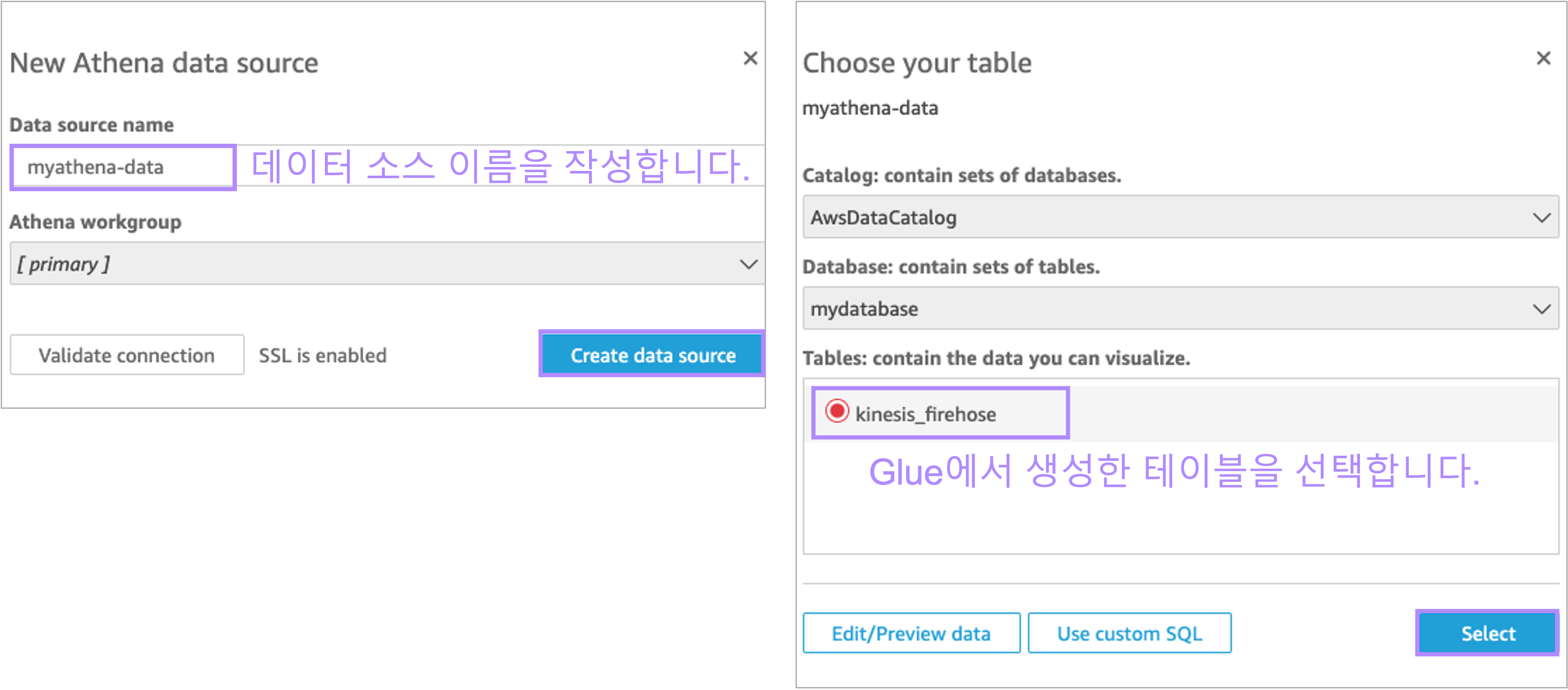
이제 실제 데이터를 로드해볼까요! 왼쪽에 있는 "Edit/Priview data"를 클릭합니다.

데이터를 로딩한 후 화면입니다.
우리는 이 화면에서 새로운 데이터를 로딩하여 조인하거나, 열의 문자열을 바꾸는 등의 작업을 할 수 있습니다!
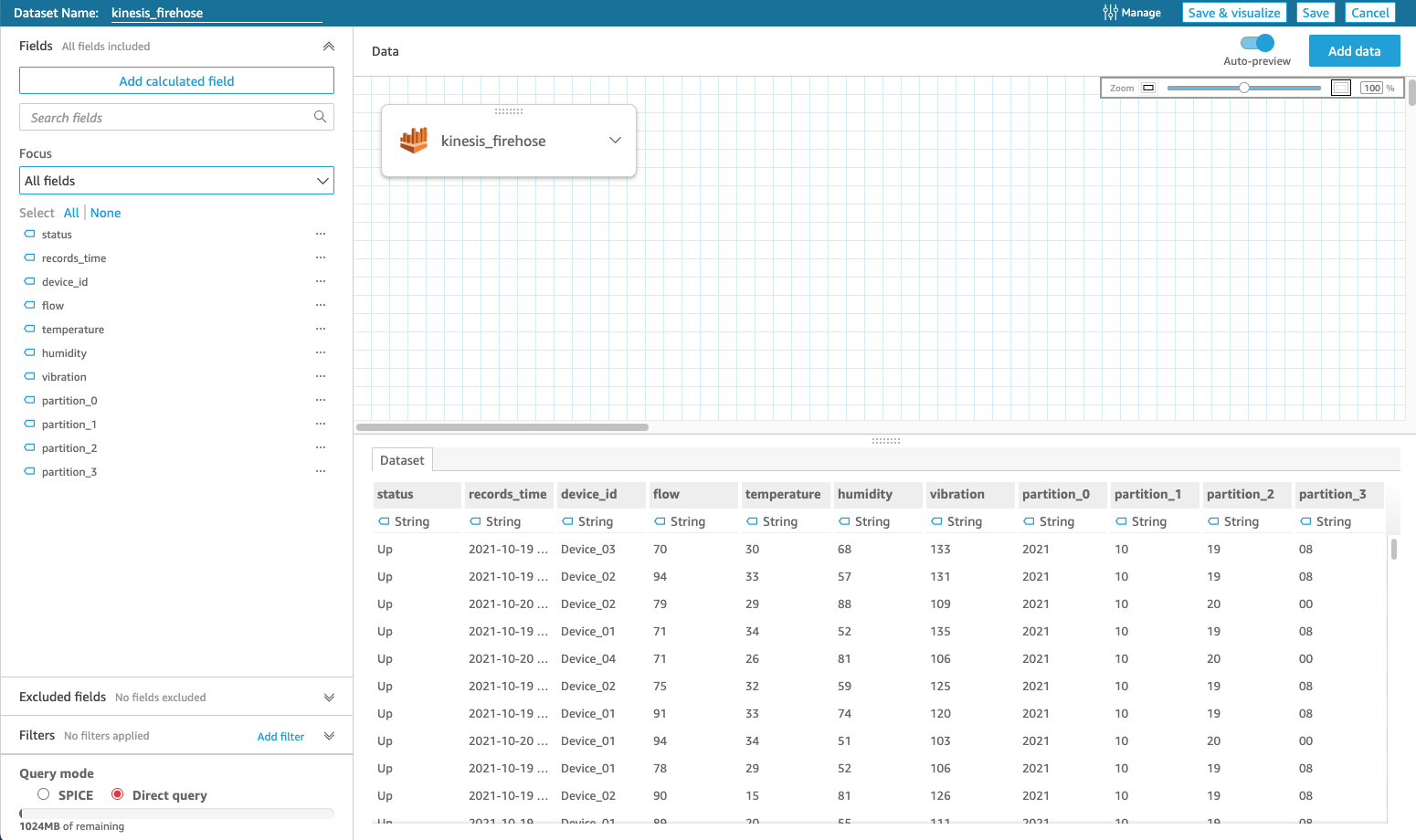
이제 데이터 타입을 알맞게 바꿔봅시다.
날짜와 숫자 타입을 지정합니다. (날짜의 경우, yyyy-MM-dd HH:mm:ss.SSSSSS 이 포멧으로 해주시면 됩니다!)
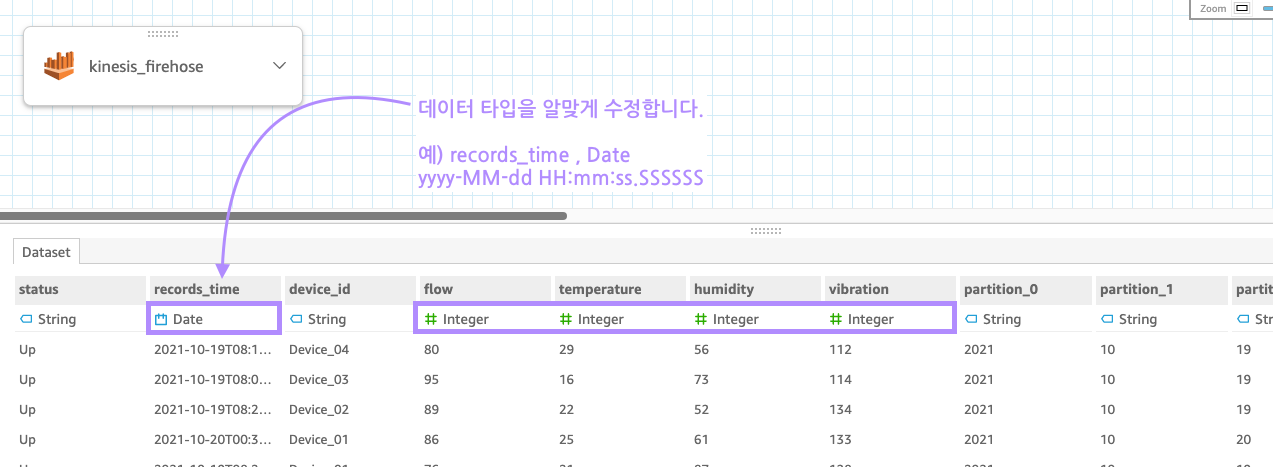
알맞게 수정 했으면, 이제 시각화를 해봐야죠!!!
왼쪽 상단에 "Save & visualize"를 클릭합니다.
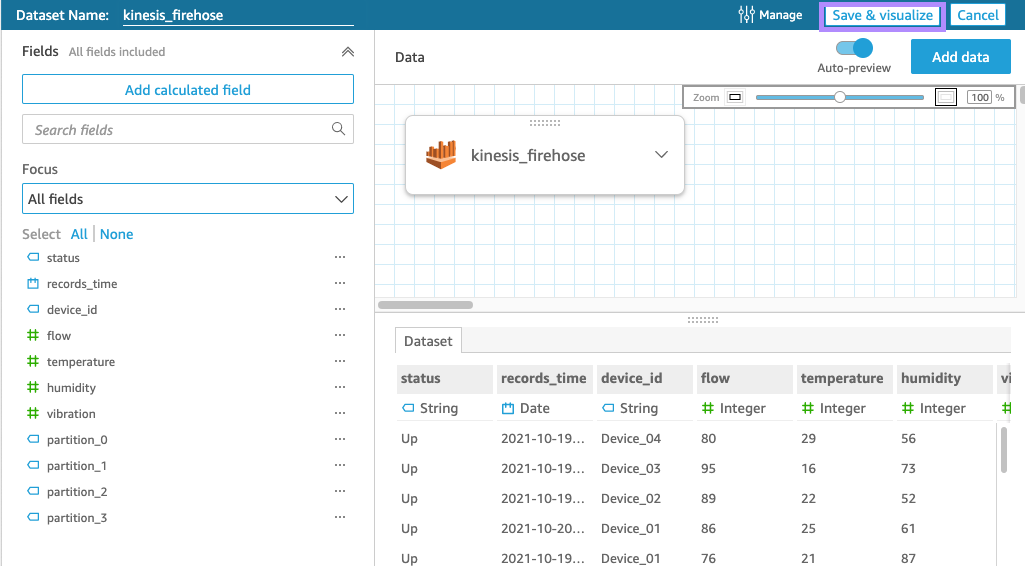
이제 여기에서 원하는 그래프를 그려줍니다.
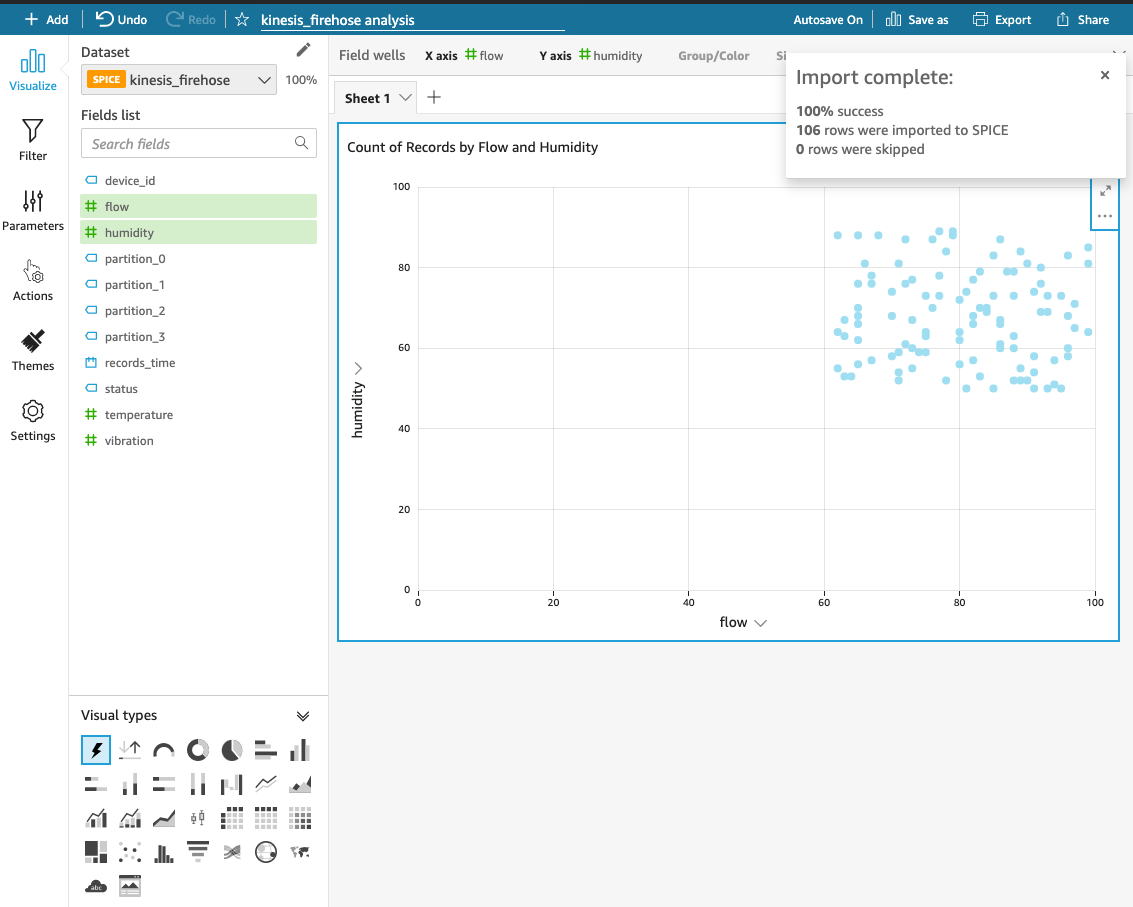
저는 이렇게 허접하게 뭔가 꾸며 (?) 봤어요.

사실, 데이터 분석 및 시각화는 데이터를 핸들링 하는것도 중요하지만 데이터가 가진 의미와 가치를 잘 알아야 합니다.
그래야 정말 잘 할수있어요!!
여기까지 고생많으셨습니다!!!!
뿅!!!