이 포스팅은 이전포스팅과 이어집니다 :)

지금까지 하나의 노드에 Java와 하둡을 설치하고, 하둡 설정파일을 수정했습니다.
이번 포스팅에서는 각 노드에 맞게 설정을 변경해보도록 하겠습니다 !!
1. Master서버 설정
이번 단계에서는 Master 서버의 설정을 변경합니다 :)
Master 서버에 SSH로 접속합니다.
1) Hostname 변경
hostnamectl 명령어를 통해 호스트 이름을 변경합니다.
sudo hostnamectl set-hostname master.hadoop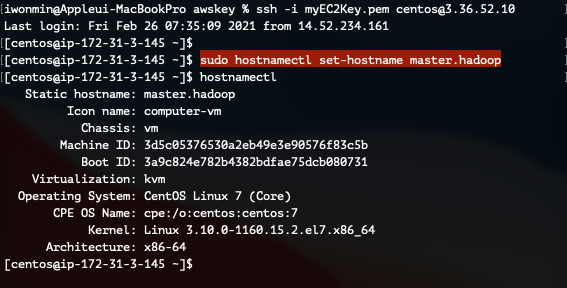
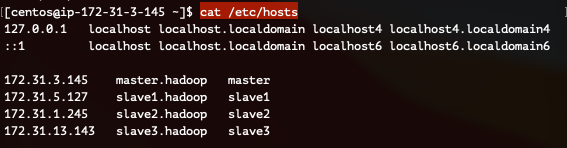
2) /etc/hosts 파일 수정
hosts파일을 수정합니다.
hosts 파일을 수정하기 전, EC2콘솔에서 각 인스턴스의 프라이빗IP주소를 알아둡니다 :)
sudo vi /etc/hosts<호스트IP> <호스트 Name>
172.31.3.145 master.hadoop master
172.31.5.127 slave1.hadoop slave1
172.31.1.245 slave2.hadoop slave2
172.31.13.143 slave3.hadoop slave3
3) SSH 키 생성 및 SSH 설정 변경
ssh-keygen 명령어로 SSH키를 생성하고 SSH로 접속 가능하도록 /etc/ssh/sshd_config 파일을 수정합니다.
* 주의 * 지금 하는 SSH설정은 매우 취약한 설정이며, 테스트 용도로만 사용하셔야 합니다.
먼저, SSH 키를 생성합니다.
sudo ssh-keygen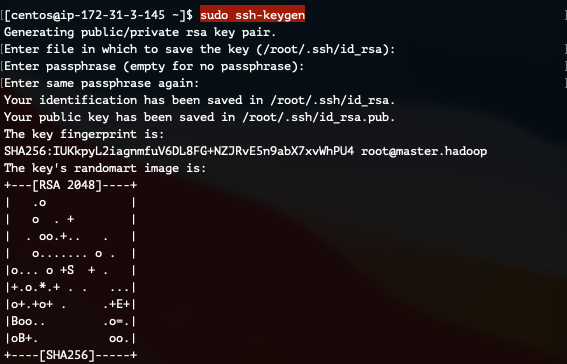
이제 ssh 설정파일을 수정합니다.
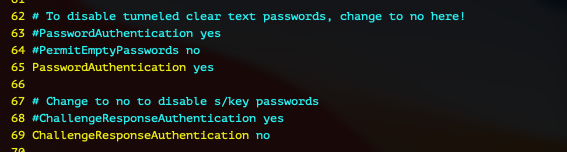
sudo vi /etc/ssh/sshd_config 먼저 2개를 변경할건데, 38번째 줄의 "PermitRootLogin" 의 주석을 해제합니다.

그리고 65번째 줄의 "PasswordAuthentication" 를 yes로 변경합니다.
저장후 설정파일을 리로드하기 위해 ssh 데몬을 재시작 합니다.
sudo systemctl restart sshdRoot 계정의 비밀번호를 생성합니다.
sudo passwd root
4) Slaves 파일 설정
이 설정은 Master 서버에서만 진행합니다!
/usr/local/hadoop-2.10.1/etc/hadoop/slaves 파일은 Slave가 될 노드들을 명시해주어야 합니다.
vi 편집기로 slaves 파일의 설정을 변경해줍니다.
vi /usr/local/hadoop-2.10.1/etc/hadoop/slavesslave1
slave2
slave3

이제 다음으로 넘어갑니다.
2. Slave1~3 서버 설정
이번 단계에서는 Slave 서버의 설정을 변경합니다 :)
아래 순서대로 각 Slave1, Slave2, Slave3에서 모두 실행시켜주세요!!
Slave 서버에 SSH로 접속합니다.
1) Hostname 변경
hostnamectl 명령어를 통해 호스트 이름을 변경합니다.
각 호스트 이름에 맞게 변경합니다.
sudo hostnamectl set-hostname slave1.hadoop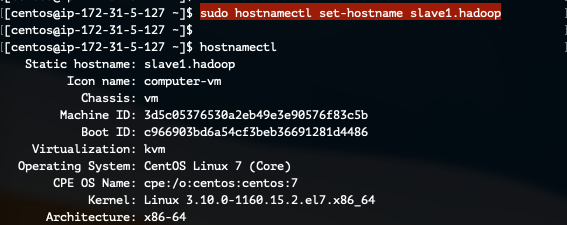
2) /etc/hosts 파일 수정
hosts파일을 수정합니다.
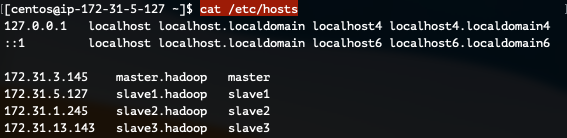
sudo vi /etc/hosts<호스트IP> <호스트 Name>
172.31.3.145 master.hadoop master
172.31.5.127 slave1.hadoop slave1
172.31.1.245 slave2.hadoop slave2
172.31.13.143 slave3.hadoop slave3
3) SSH 키 생성 및 SSH 설정 변경
ssh-keygen 명령어로 SSH키를 생성하고 SSH로 접속 가능하도록 /etc/ssh/sshd_config 파일을 수정합니다.
* 주의 * 지금 하는 SSH설정은 매우 취약한 설정이며, 테스트 용도로만 사용하셔야 합니다.
먼저, SSH 키를 생성합니다.
sudo ssh-keygen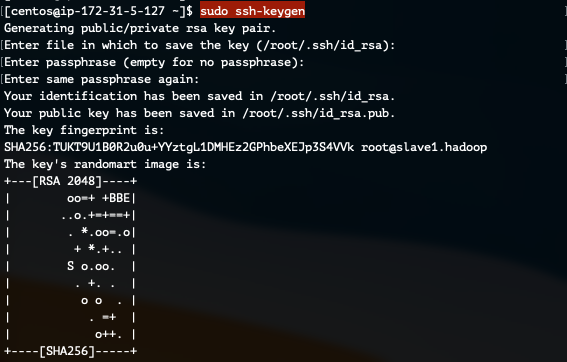
이제 ssh 설정파일을 수정합니다.
sudo vi /etc/ssh/sshd_config 먼저 2개를 변경할건데, 38번째 줄의 "PermitRootLogin" 의 주석을 해제합니다.
그리고 65번째 줄의 "PasswordAuthentication" 를 yes로 변경합니다.
저장후 설정파일을 리로드하기 위해 ssh 데몬을 재시작 합니다.
sudo systemctl restart sshdRoot 계정의 비밀번호를 생성합니다.
sudo passwd root
이제 다음으로 넘어갑니다.
3. SSH 키 교환
이 단계는 각 서버에서 동일하게 실행합니다! (Master, Slave1, Slave2, Slave3 4대의 시스템 모두에서 진행합니다)
적다보니 Master서버에서만 진행해도 되지 않았나 하는 의문이 드는데... 다음에 다시 테스트 해보겠습니다!! 일단 지금은 이렇게 갑니다!
이 설정을 완료하면 ssh 명령어로 어떤 서버에나 그냥 접속할 수 있게 됩니다!!
Master 서버와 키를 교환합니다.
ssh-copy-id root@master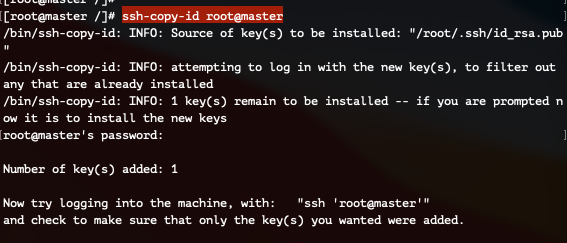
slave1 서버와 키를 교환합니다.
ssh-copy-id root@slave1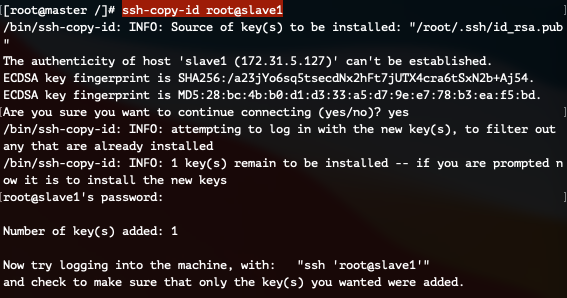
slave2 서버와 키를 교환합니다.
ssh-copy-id root@slave2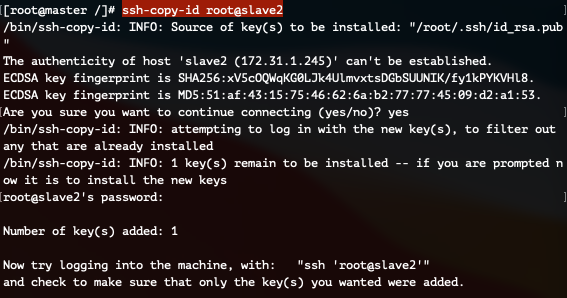
slave3 서버와 키를 교환합니다.
ssh-copy-id root@slave3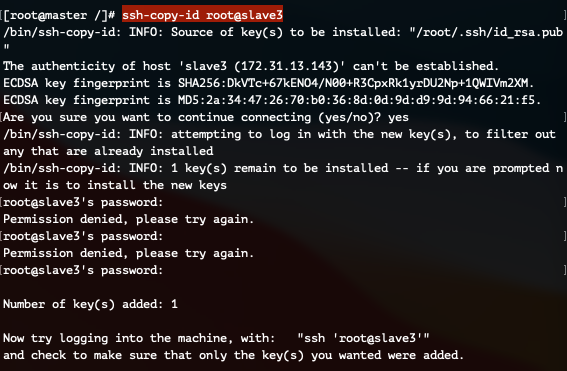
모두 완료 되었다면! 다음 단계로 넘어갑니다.
4. HDFS 파일 포멧
처음 디스크를 사용할때, OS에 맞게 파일 시스템을 포멧하는것 처럼, HDFS를 시작하기 전 포멧을 진행합니다 :)
NameNode 포멧은 Master 서버에서, DataNode 포멧은 Slave1, Slave2, Slave3 서버에서 진행합니다!
1) NameNode 포멧
먼저 마스터 서버에서 아래의 명령어를 실행합니다.
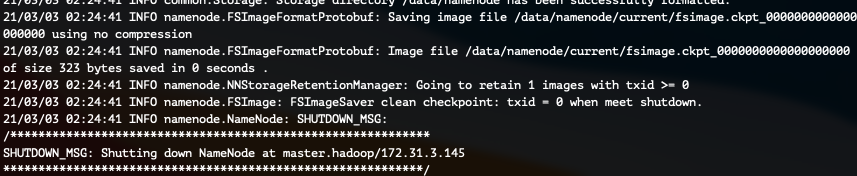
명령어 실행 후 /data 디렉터리가 생성된것을 확인할 수 있습니다.
/usr/local/hadoop-2.10.1/bin/hdfs namenode -format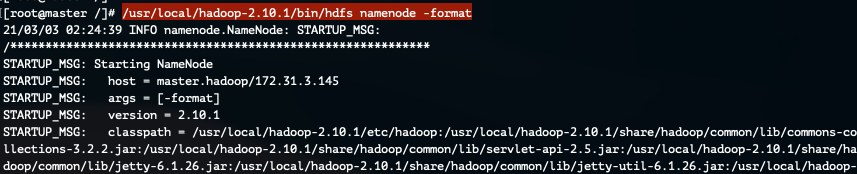
(중간생략)
2) DataNode 포멧
Slave 노드 (DataNode) 3대 모두에서 아래의 명령어를 실행합니다.
마찬가지로, 명령어 실행 후 /data 경로가 생성됨을 확인할 수 있습니다.
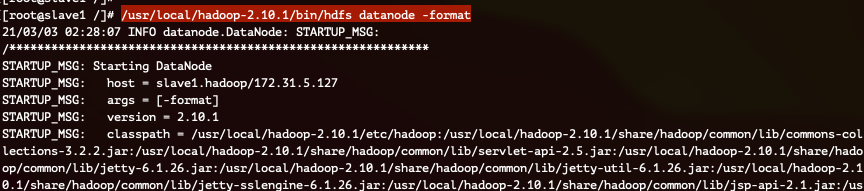
(중간생략)
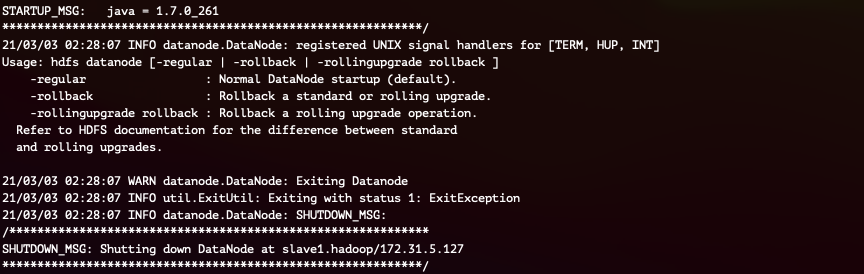
5. HDFS & YARN 시작하기
하둡 클러스터를 실행하기 위해서, HDFS를 시작한 후에 YARN을 실행시켜주면 됩니다.
HDFS는 말 그대로 파일시스템, 그리고 YARN은 리소스 매니저입니다 :)
1) HDFS 시작하기
아래 명령어로 HDFS를 시작합니다.
/usr/local/hadoop-2.10.1/etc/hadoop/slaves에 등록된 노드에 모두 SSH Trusted Access 가능하다면,
아래 명령어 한줄로 모든 노드의 데몬을 띄울 수 있습니다 :)
/usr/local/hadoop-2.10.1/sbin/start-dfs.sh
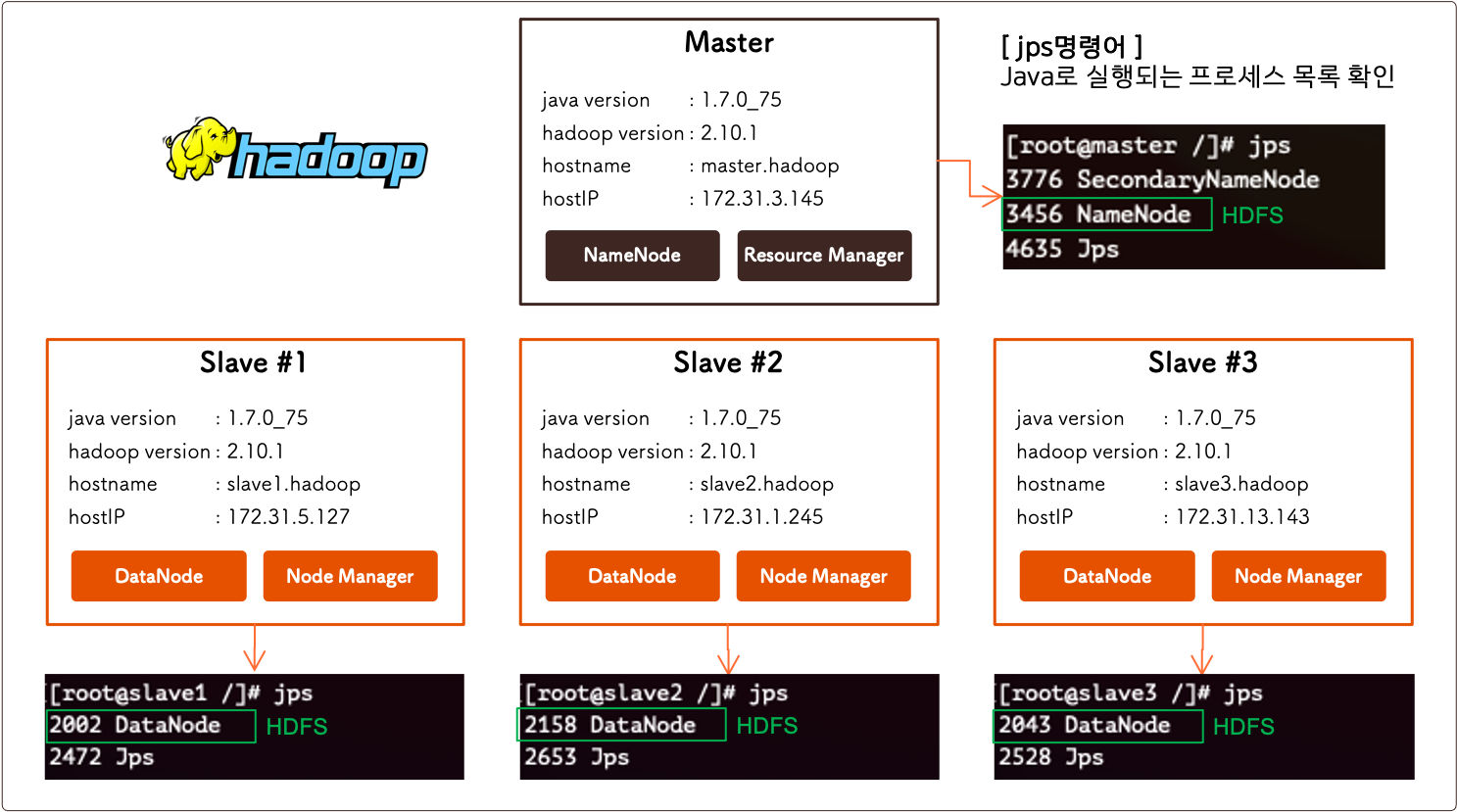
이제 각 노드에서는 아래 그림과 같이, Master 노드에서는 NameNode 데몬이 동작하고, Slave 노드에서는 DataNode 데몬이 동작하게 됩니다.
각 데몬이 정상적으로 동작하는지 여부는 jps 명령어로 확인해 볼 수 있습니다.!
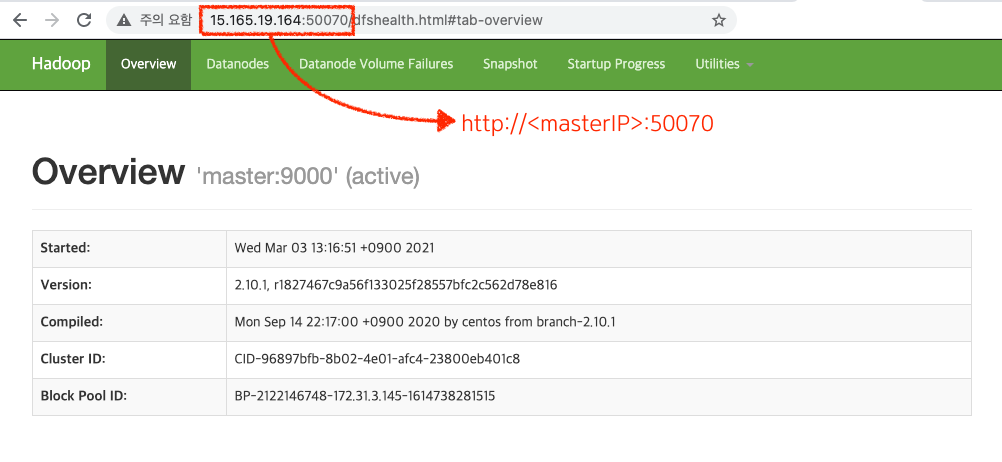
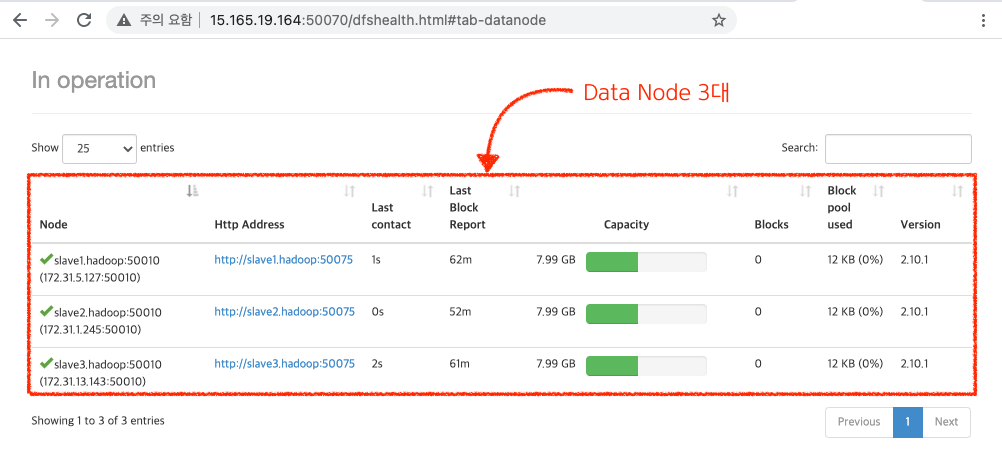
HDFS를 정상적으로 시작하셨다면 웹브라우저로 접속 가능합니다:)
http://<Master IP>:50070
2) YARN (Resource Manager) 시작하기
아래 명령어로 YARN를 시작합니다.
/usr/local/hadoop-2.10.1/etc/hadoop/slaves에 등록된 노드에 모두 SSH Trusted Access 가능하다면,
아래 명령어 한줄로 모든 노드의 데몬을 띄울 수 있습니다 :)
/usr/local/hadoop-2.10.1/sbin/start-yarn.sh 
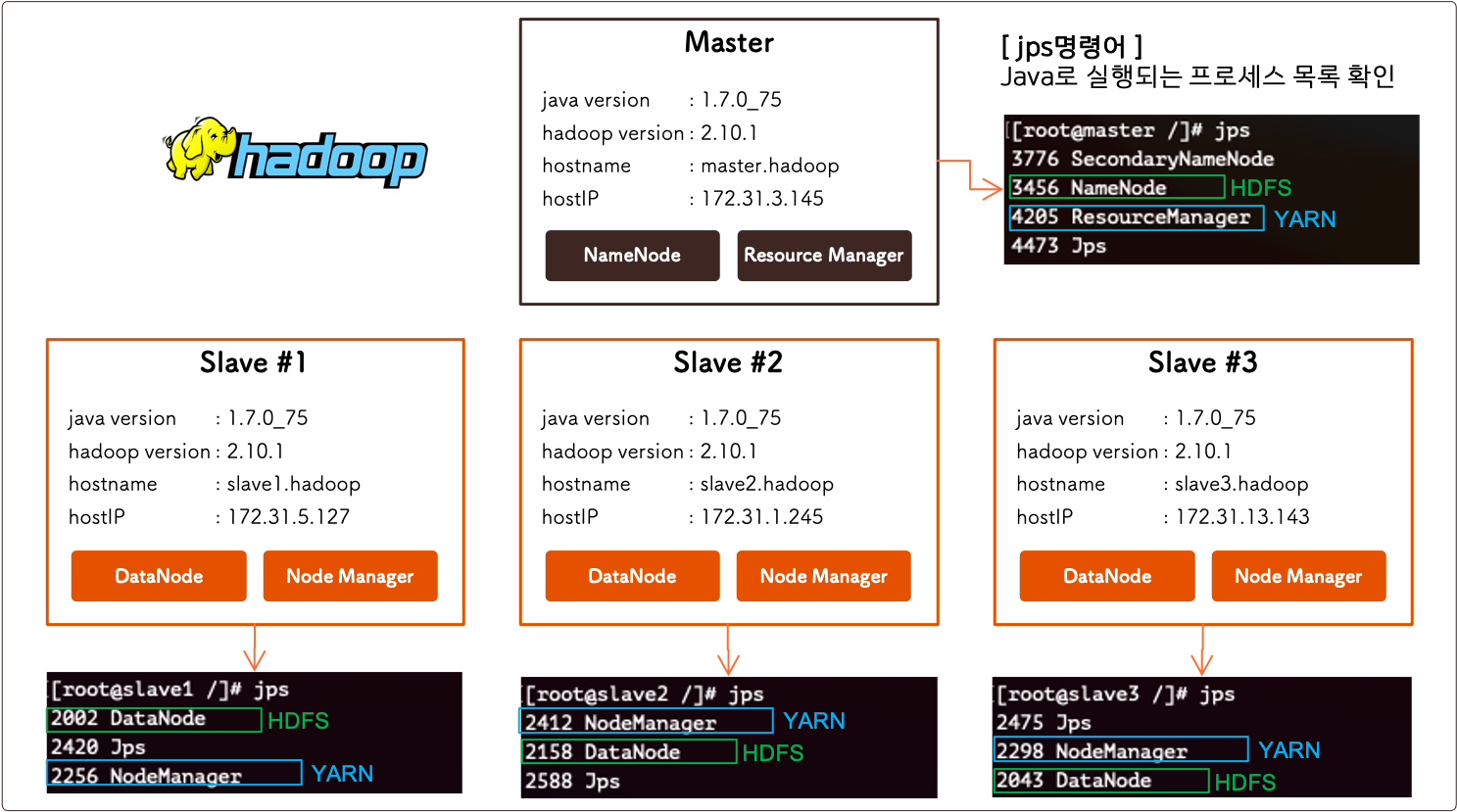
Yarn을 정상적으로 시작 하셨다면, 웹브라우저에서도 접속 가능합니다 :)
http://<Master IP>:8088
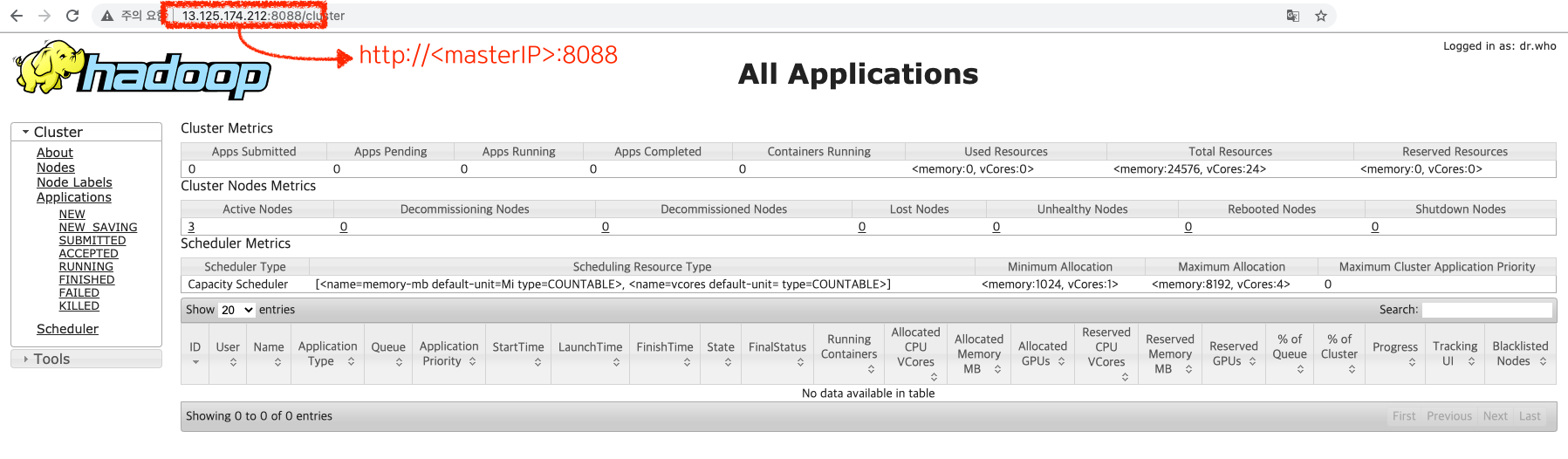
이것저것 클릭해서 확인해보세요!
여기까지 진행 하셨다면 HDFS를 구축하는 부분은 완료 되었습니다!! 🤗🤗🤗
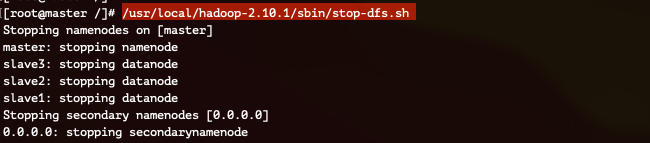
5. HDFS & YARN 종료하기
시작과 마찬가지로 종료할때에도 순서에 맞춰 진행해주시면 됩니다 :)
HDFS & YARN을 종료하는 것은 아래 두 명령어를 순서대로 진행하시거나 stop-all.sh를 실행시켜주셔도 됩니다 :)
/usr/local/hadoop-2.10.1/sbin/stop-yarn.sh 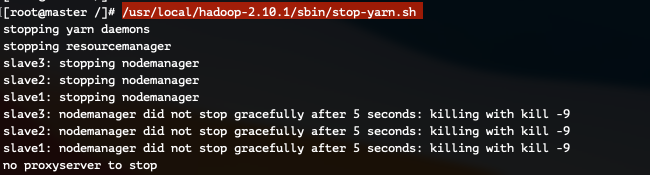
/usr/local/hadoop-2.10.1/sbin/stop-dfs.sh