이 포스팅은 이전 포스팅과 이어집니다. 😘
Hadoop HDFS(3.3)+Spark(3.1.1)! 무작정 따라하기 #2
Hadoop HDFS(3.3)+Spark(3.1.1)! 무작정 따라하기 #2
이 포스팅은 이전 포스팅과 이어집니다. 이전 포스팅에서 EC2 한대를 생성하여 그 인스턴스에 필요한 소프트웨어를 모두 설치하고, 환경변수와 설정파일을 수정했습니다. 그리고 그 인스턴스를
1mini2.tistory.com
이전 포스팅 #1 ~ #2에서 모든 인프라 구축이 완료 되었습니다.
이제 4대의 인스턴스에 HDFS, YARN, Spark 클러스터가 운영중입니다. 🎉🎉🎉🎉
이번 단계에JupyterNotebook을 설치하고 실행해보도록 하겠습니다.😘
하지만 그 전에! 모든 서비스가 정상인지 확인해봅시다!!
인프라 구성이 완료된 시점인 지금!!
지금부터는 모든 명령어수행은 Master노드에서만 진행합니다.
1. HDFS 서비스 확인하기
HDFS 서비스는 CLI 혹은 웹콘솔을 통해 상태를 확인할 수 있습니다.
[ HDFS CLI ]
[root@master ~]# /usr/local/hadoop-3.3.0/bin/hdfs dfsadmin -report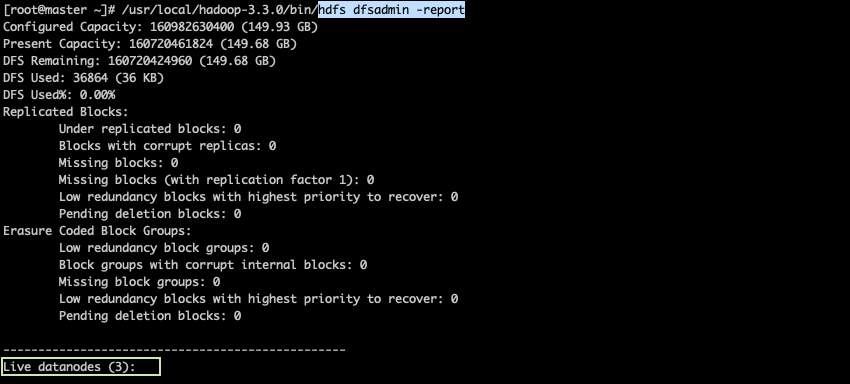
[ HDFS WEB UI ]
- http://<master node IP>:9870
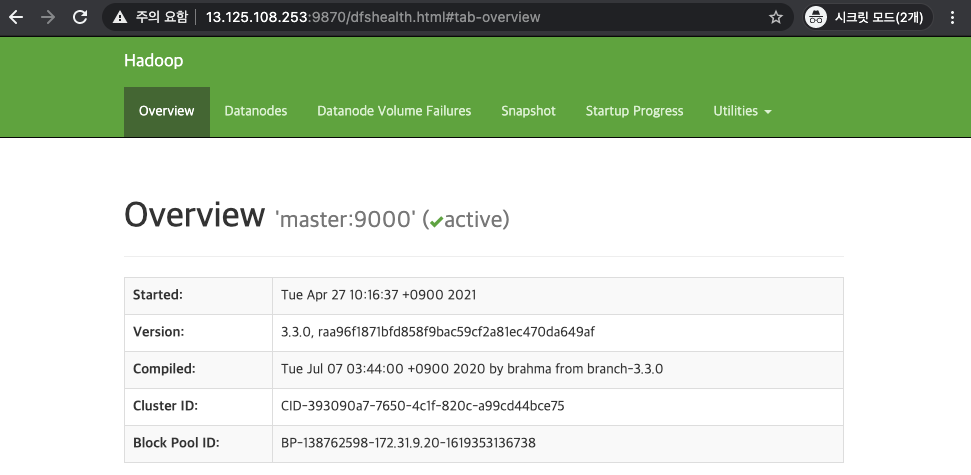
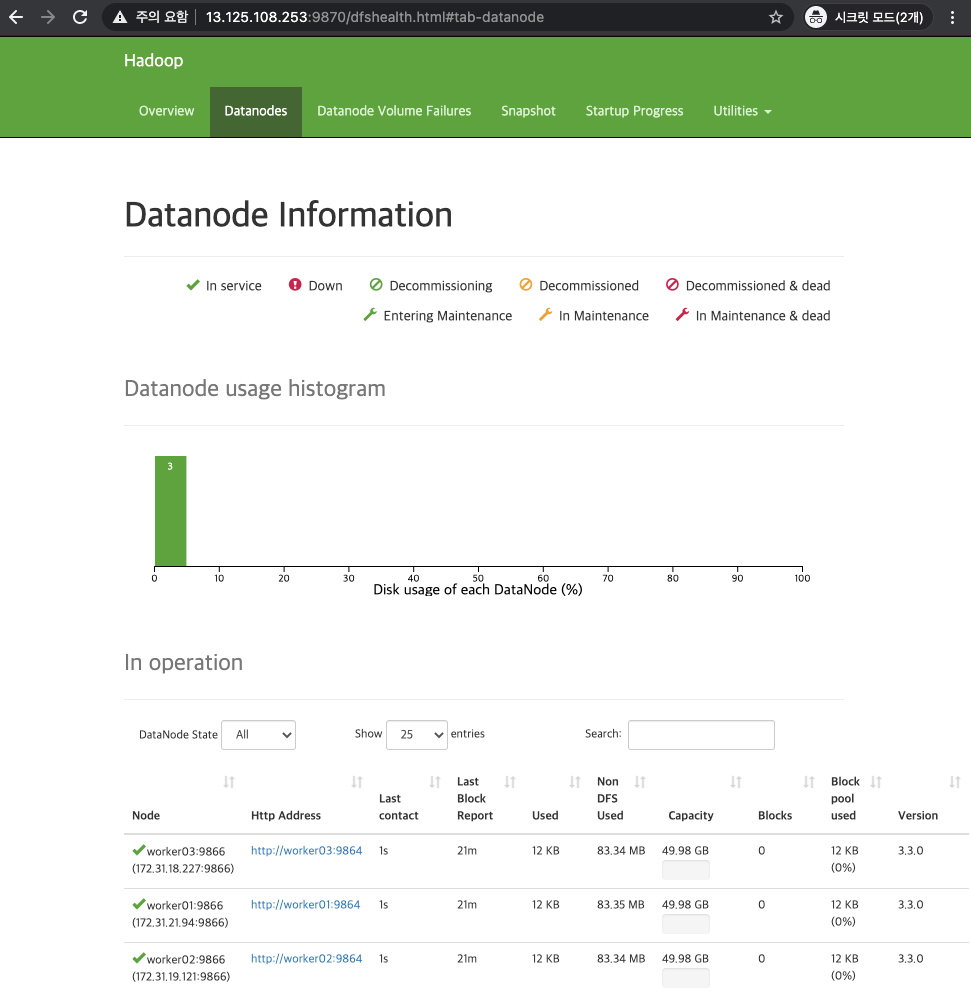
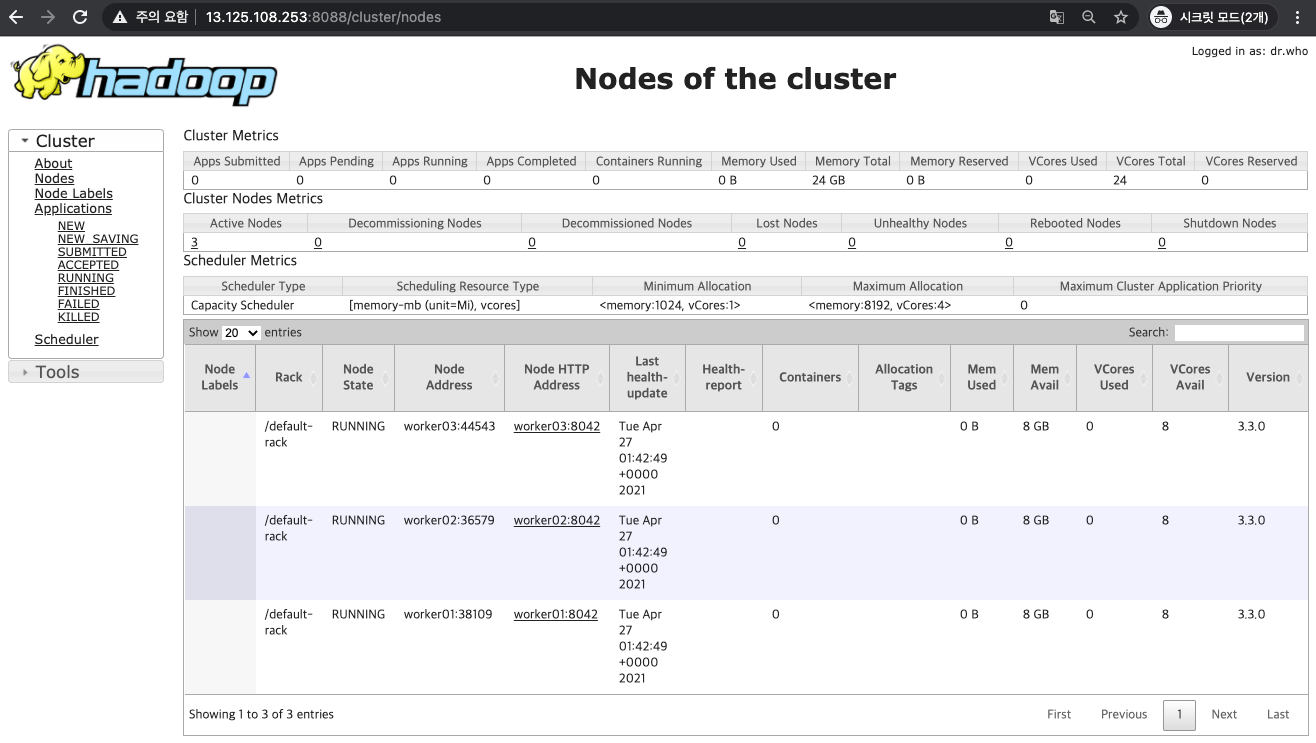
2. Yarn 서비스 확인하기
YARN 서비스도 CLI 혹은 웹콘솔을 통해 상태를 확인할 수 있습니다.
[ YARN CLI ]
[root@master ~]# /usr/local/hadoop-3.3.0/bin/yarn node -list
[ YARN WEB UI ]
- http://<master node IP>:8088
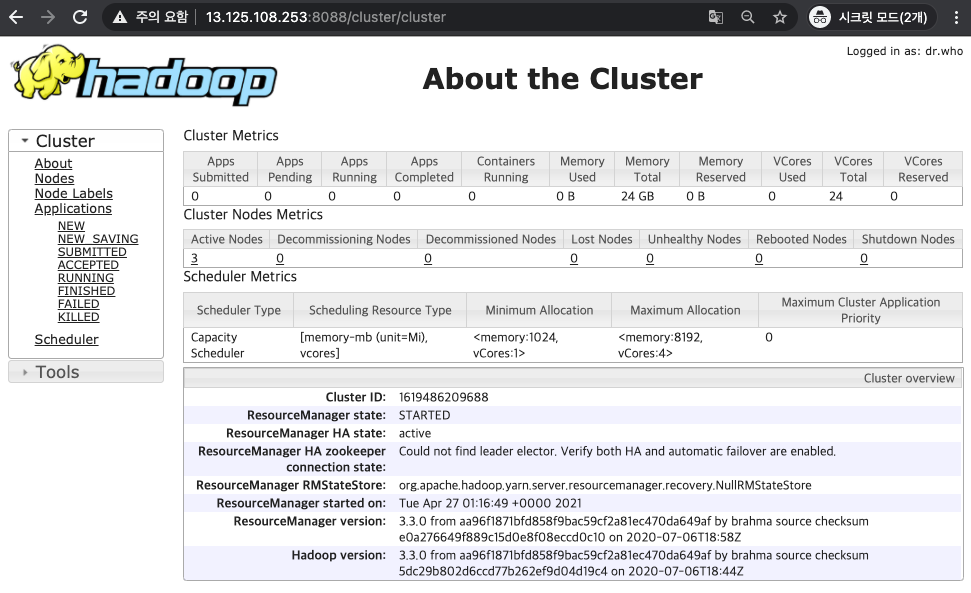
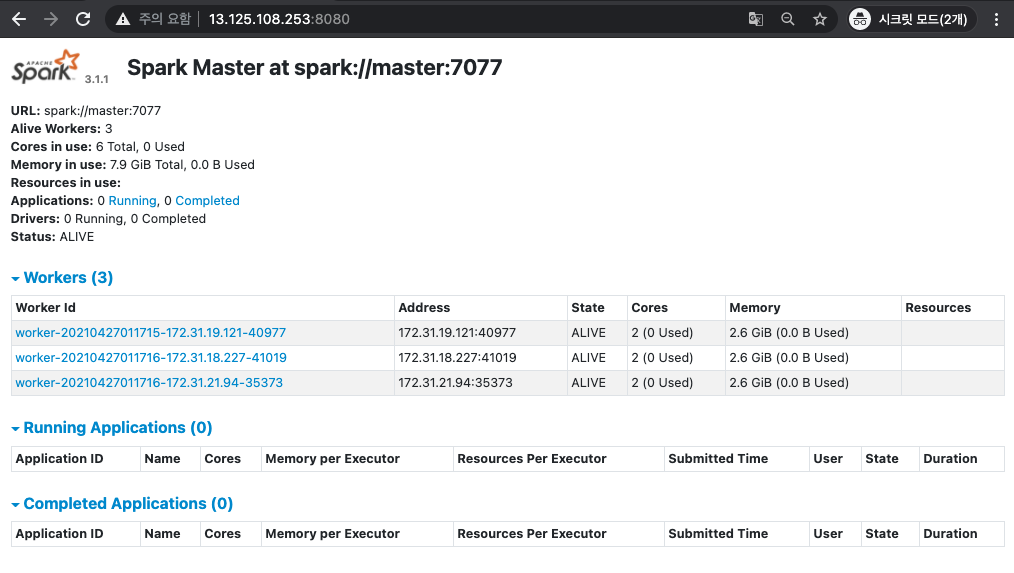
3. Spark 서비스 확인하기
Spark의 서비스는 WEB UI에서 확인합니다!!
[ Spark WEB UI ]
- http://<master node IP>:8080
4. Python 3 & Conda (jupyterNotebook) & findspark 설치하기
1) Python 3 설치
저는 Amazon Linux2 OS를 사용하고 있습니다.
여기에는 이미 Python 3 최신버전이 설치되어 있습니다.
만약, 설치되어있지 않다면, "yum install python3 -y" 명령어로 python 3를 설치해주세요.
python3 설치 버전을 확인해봅니다.
[root@master ~]# python3 --version
2) JupyterNotebook 설치
miniconda(설치 링크)로도 설치가 가능하지만, 저는 가장 간편한 방법인 pip을 통해 jupyter를 설치하겠습니다.
[root@master ~]# pip3 install jupyter벌써 설치가 완료 되었습니다.
아래 명령어를 실행하여 프로세스가 실행된다면 다음으로 넘어갑니다!!!
[root@master ~]# jupyter notebook --allow-root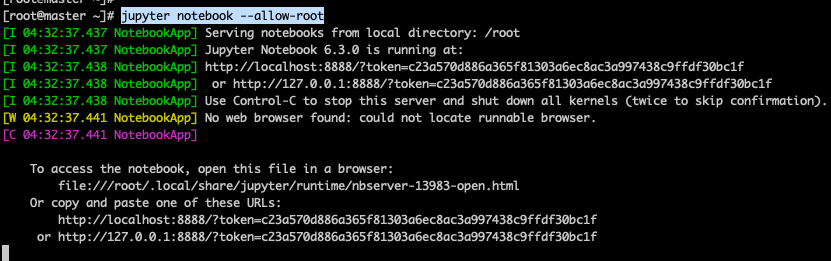
3) findSpark 설치
findspark란? SparkContext (Spark Cluster endpoint) 를 findSpark 패키지로 쉽게 찾을 수 있습니다. 만약 이 라이브러리를 사용하지 않는다면 Jypyter에서 Spark용도의 프로필을 별도로 사용해서 사용합니다.
[root@master ec2-user]# pip3 install findspark
5. Jupyter Notebook 실행하기
Jupyter Notebook 실행 전 설정파일을 수정해줍니다!
먼저, 설정파일을 생성합니다.
[root@master ~]# jupyter notebook --generate-config그리고 Password를 생성합니다.
[root@master ~]# ipython
Python 3.7.9 (default, Feb 18 2021, 03:10:35)
Type 'copyright', 'credits' or 'license' for more information
IPython 7.22.0 -- An enhanced Interactive Python. Type '?' for help.
In [1]: from notebook.auth import passwd
In [2]: passwd()
Enter password: // 사용할 비민번호 입력
Verify password:
Out[2]: 'argon2:$argon2id$v=19$m=10240,t=1 ... ' //복사해놓기!
In [3]: exit()그리고 Jupyter Notebook의 홈디렉터리를 만들어줍니다.
[root@master ~]# mkdir /root/jupyter_dir이제 설정파일을 수정합니다.
[root@master ~]# vim /root/.jupyter/jupyter_notebook_config.pyc.NotebookApp.ip = '0.0.0.0'
c.NotebookApp.password ='argon2:$argon2id$v=19$m=10240,t=10,p=8$t+Ki3Y…’
c.NotebookApp.notebook_dir = '/root/jupyter_dir/
자~! 이제 실행해봅시다!!!!
[root@master ~]# jupyter notebook --allow-root
웹브라우저에서 실행하면 이렇게 보입니다.!!
비밀번호를 치고 로그인해봅니다.
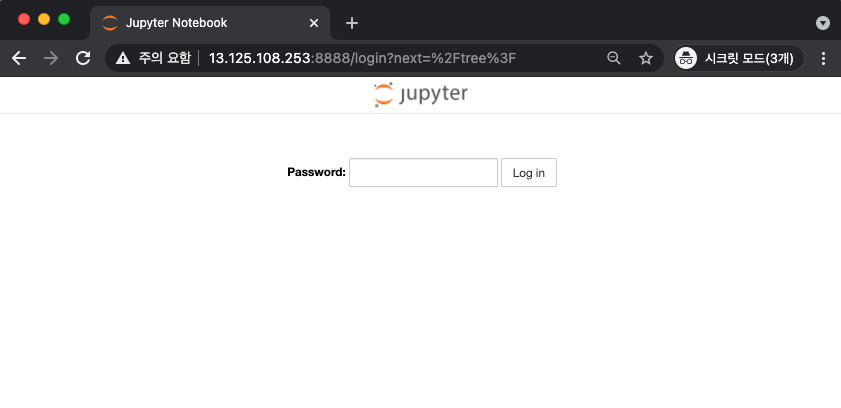
아무것도 없죠!!!
한번 findspark 써봅시다!!
그냥 어플리케이션을 생성하는것 까지 입니다!!
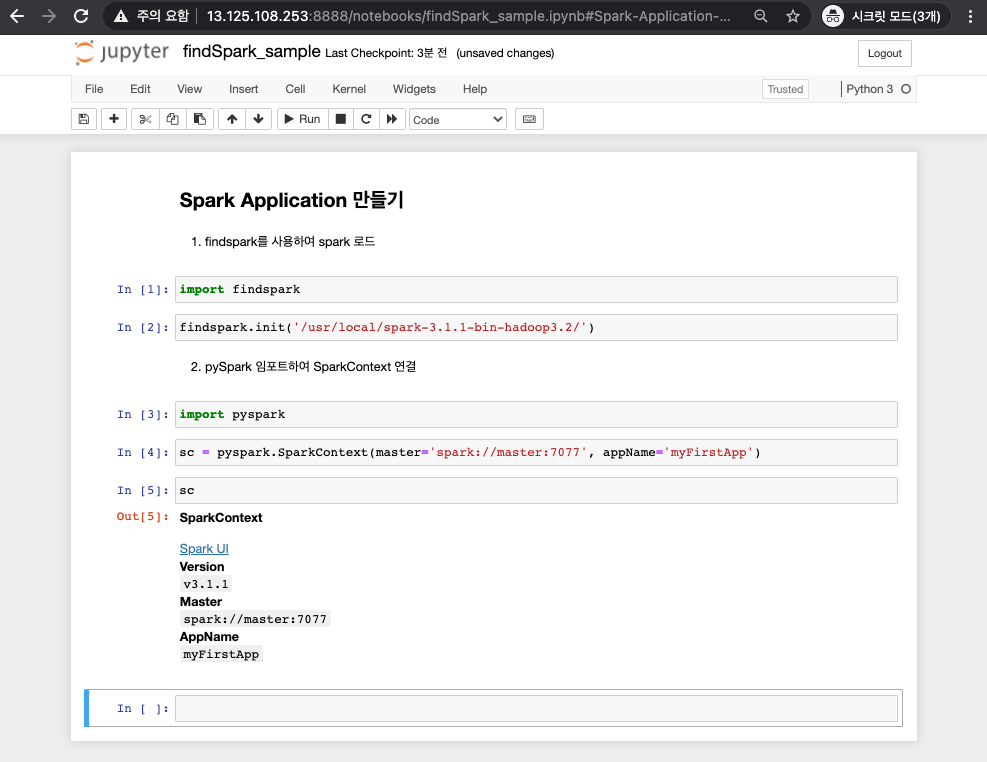
import findspark
findspark.init('/usr/local/spark-3.1.1-bin-hadoop3.2/')
import pyspark
sc = pyspark.SparkContext(master='spark://master:7077', appName='myFirstApp')
sc
이 코드를 실행하면, Spark Application이 실행됩니다.
웹 UI에서도 어플리케이션이 실행되는것을 확인할 수 있습니다.
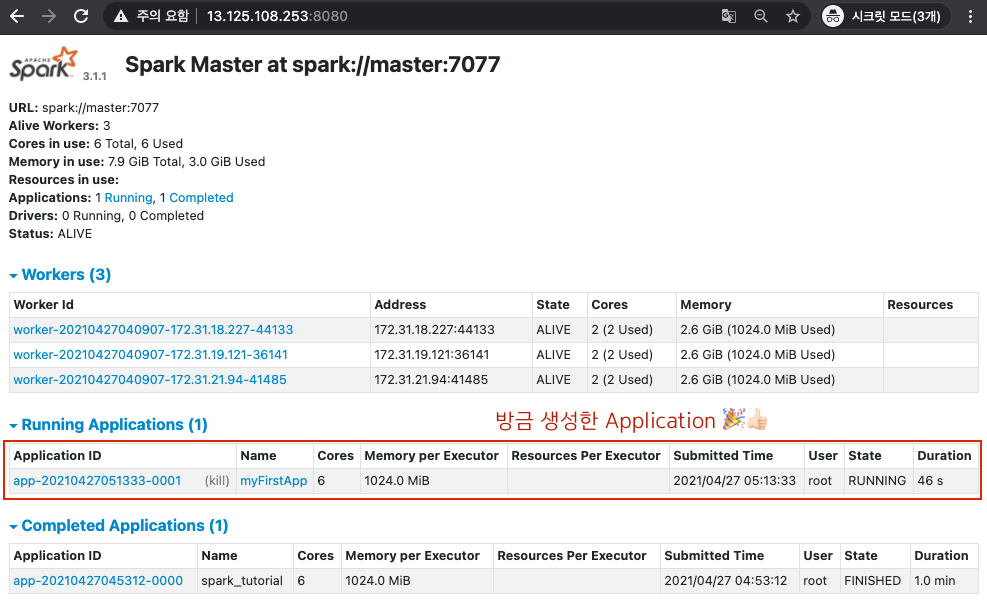
🖐🖐🖐여기서 잠깐!🖐🖐🖐
제가 작성한 이 포스팅에서, spark를 따로 띄우는데, 이렇게 되면 standalone mode 라고 합니다 🥲
포스팅한지 1년이 지났지만, 이제야 이 사실을 알았네요...
제 포스팅을 보고 따라하셨던 분들 이 부분을 참고해주세요 🥲
다음에 더 공부해서 좋은 내용으로 포스팅하도록 하겠습니다.
cattt님 정말 감사합니다.💙

출처: spark.apache.org/docs/latest/running-on-yarn.html