이 포스팅은 이전 포스팅과 이어집니다. 😘
Hadoop HDFS(3.3)+Spark(3.1.1)! 무작정 따라하기 #1
Hadoop HDFS(3.3)+Spark(3.1.1)! 무작정 따라하기 #1
안녕하세요 😁😁😁😁! 저번 포스팅에는 하둡 HDFS 예전 버전 (2.0)을 설치했었습니다. 이번 포스팅에는 하둡HDFS 최신버전인 3.3를 설치하고, 그 위에 Spark도 함께 설치해보려고 합니다. HDFS 3.3버
1mini2.tistory.com
이전 포스팅에서 EC2 한대를 생성하여 그 인스턴스에 필요한 소프트웨어를 모두 설치하고, 환경변수와 설정파일을 수정했습니다.
그리고 그 인스턴스를 AMI이미지로 만든 후, 복제하여 총 4대의 인스턴스를 만들었죠!
이번 포스팅에서는 이제 각 역할에 맞춰 Master/ Worker에 설정을 해주고, 클러스터를 실행해보도록 하겠습니다!!
1. Master 서버 설정하기
이번 단계에서는 Master 서버의 호스트이름 변경, hosts 파일 수정을 진행합니다.
Master로 사용할 단 하나의 서버에서만 진행합니다.
1) 호스트 이름 변경
호스트의 이름을 Master로 변경합니다.
$ sudo hostnamectl set-hostname master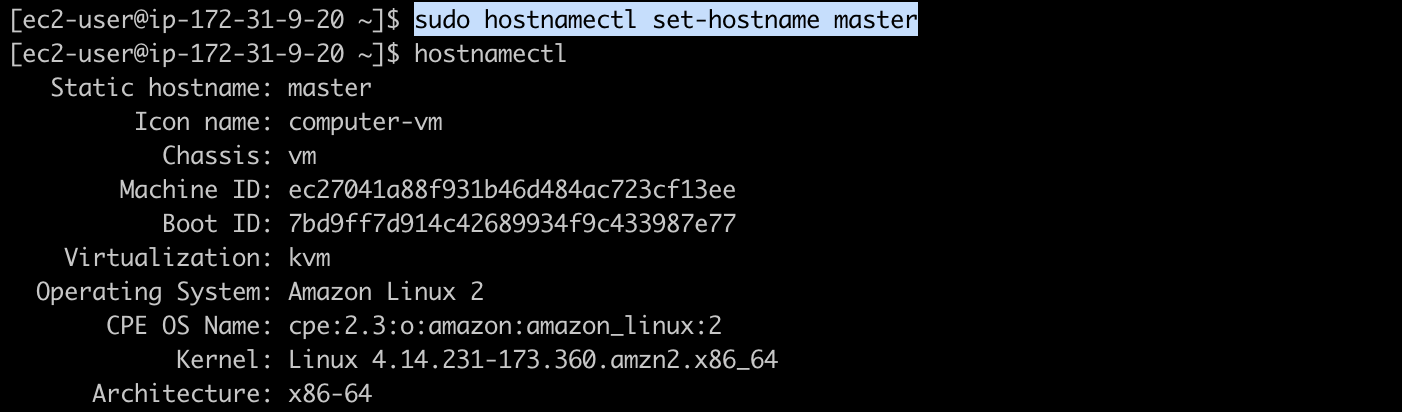
2) Hosts 파일 수정
Hosts 파일을 수정합니다. Hosts파일에는 Master 및 Worker01~03 노드의 모든 아이피&호스트명이 정의되어야 합니다.
$ sudo vim /etc/hosts
2. Worker 1~3 서버 설정하기
이번 단계에서는 Worker01~03 서버의 호스트이름 변경, hosts 파일 수정을 진행합니다.
1) 호스트 이름 변경
저는 MAC 사용 유저로, iterm 터미널로 한번에 명령어를 수행하고 있습니다.
혹시 윈도우 사용자이고, 개인이라면 x-shell같은 툴을 다운받아서 저처럼 사용할 수 있습니다.
# 각 호스트에 worker01, worker02, worker03 입력!
$ sudo hostnamectl set-hostname worker01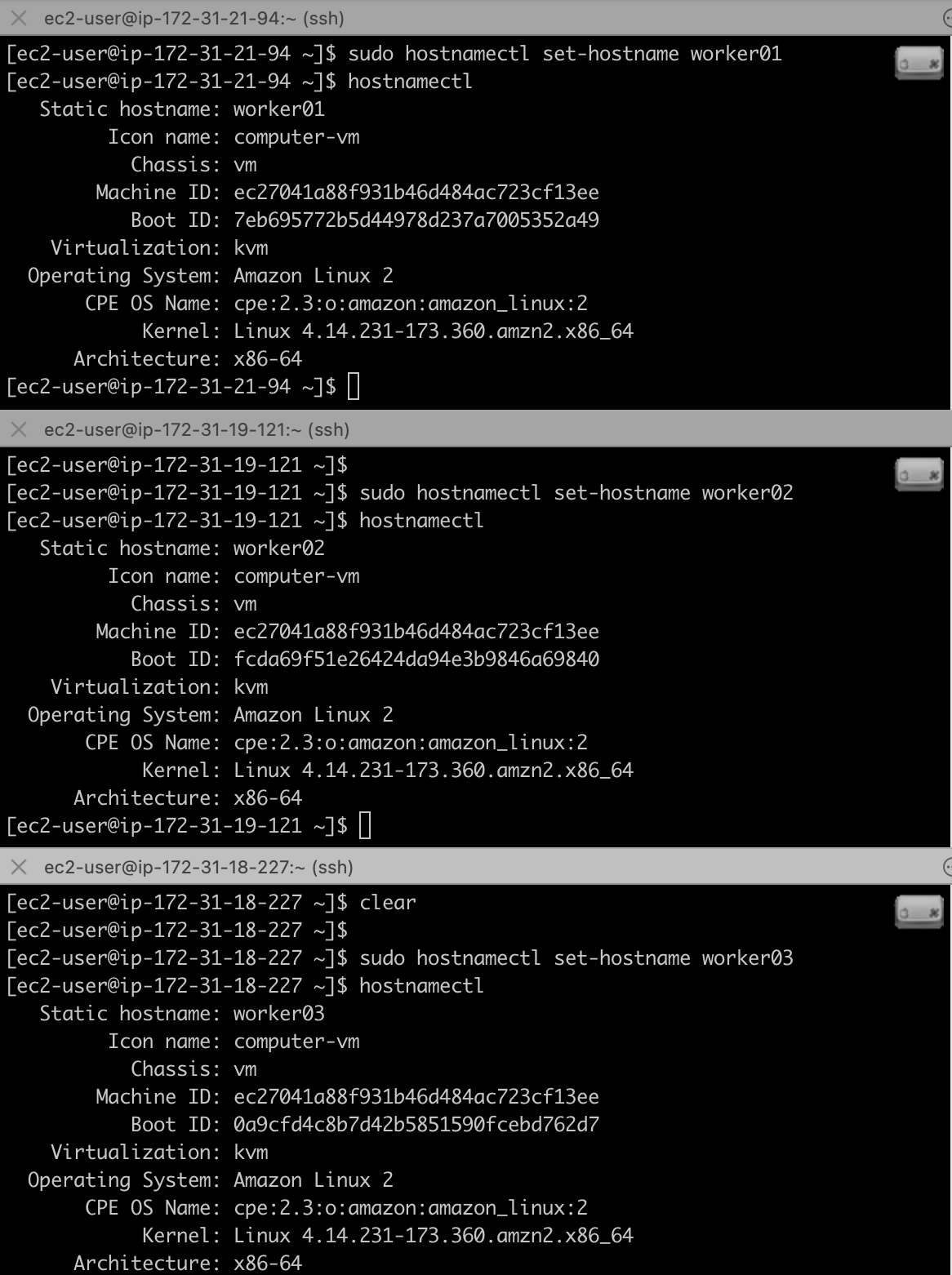
2) Hosts 파일 수정
$ sudo vim /etc/hosts
3. SSH-KEY 교환하기
이번 단계는 모든 노드에서 동일하게 수행합니다.
※주의 : 이번 단계는 구성을 편하게 하기 위해 보안에 취약한 여러가지 설정을 진행합니다.
실 운영 환경에서는 Root계정의 보호와 SSH키 교환이 취약할 수 있으니 설정에 주의하세요.
1) SSH 설정 변경하기
작업을 진행하기 전, Root 계정으로 변경합니다.
$ sudo su
이제, SSH 설정파일을 수정합니다.
# vim /etc/ssh/sshd_config
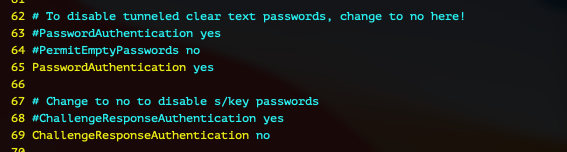
38번째 줄의 "PermitRootLogin" 의 주석을 해제합니다.

65번째 줄의 "PasswordAuthentication" 를 yes로 변경합니다.
저장후 설정파일을 리로드하기 위해 ssh 데몬을 재시작하고, Root 계정의 비밀번호를 설정합니다.
# systemctl restart sshd
# passwd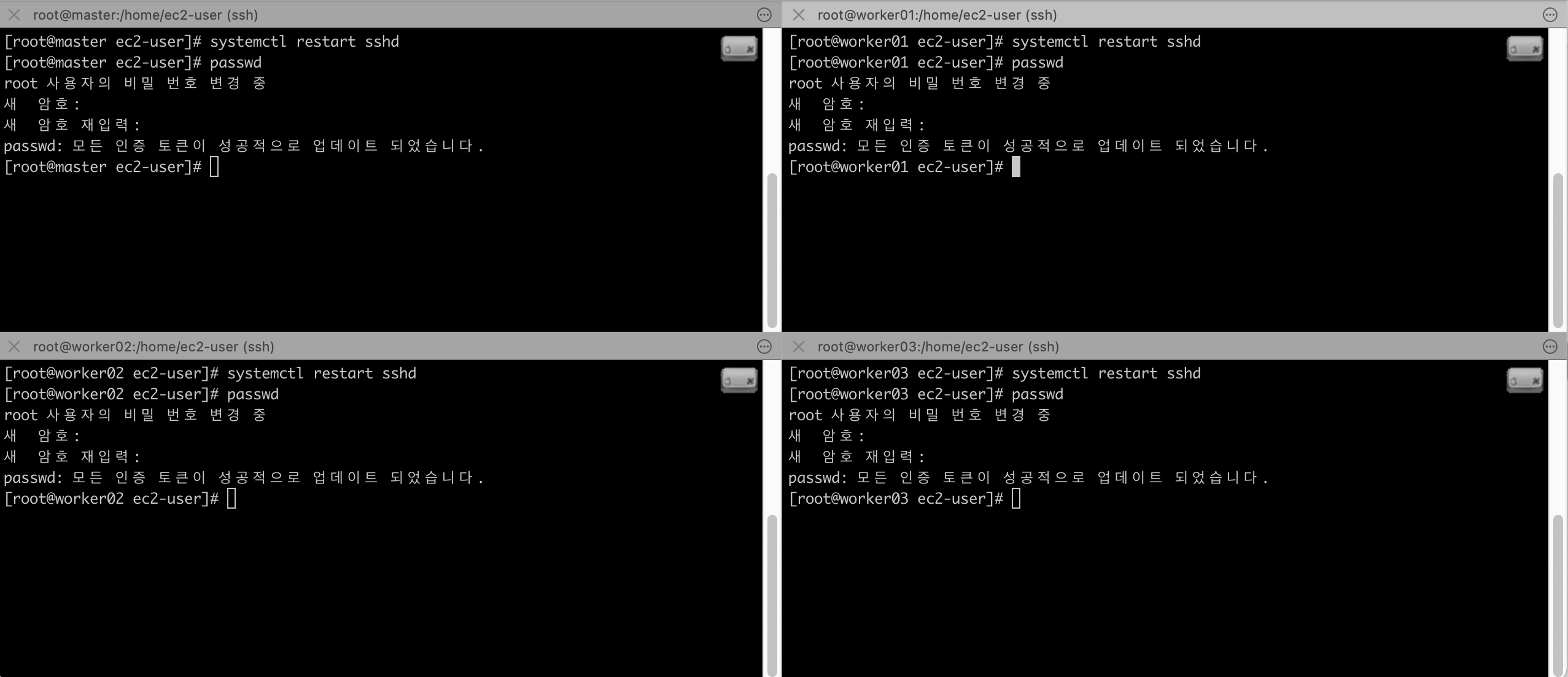
2) SSH 키 생성하기
SSK-KEY를 생성합니다. (전부 엔터 눌러주세요!)
# ssh-keygen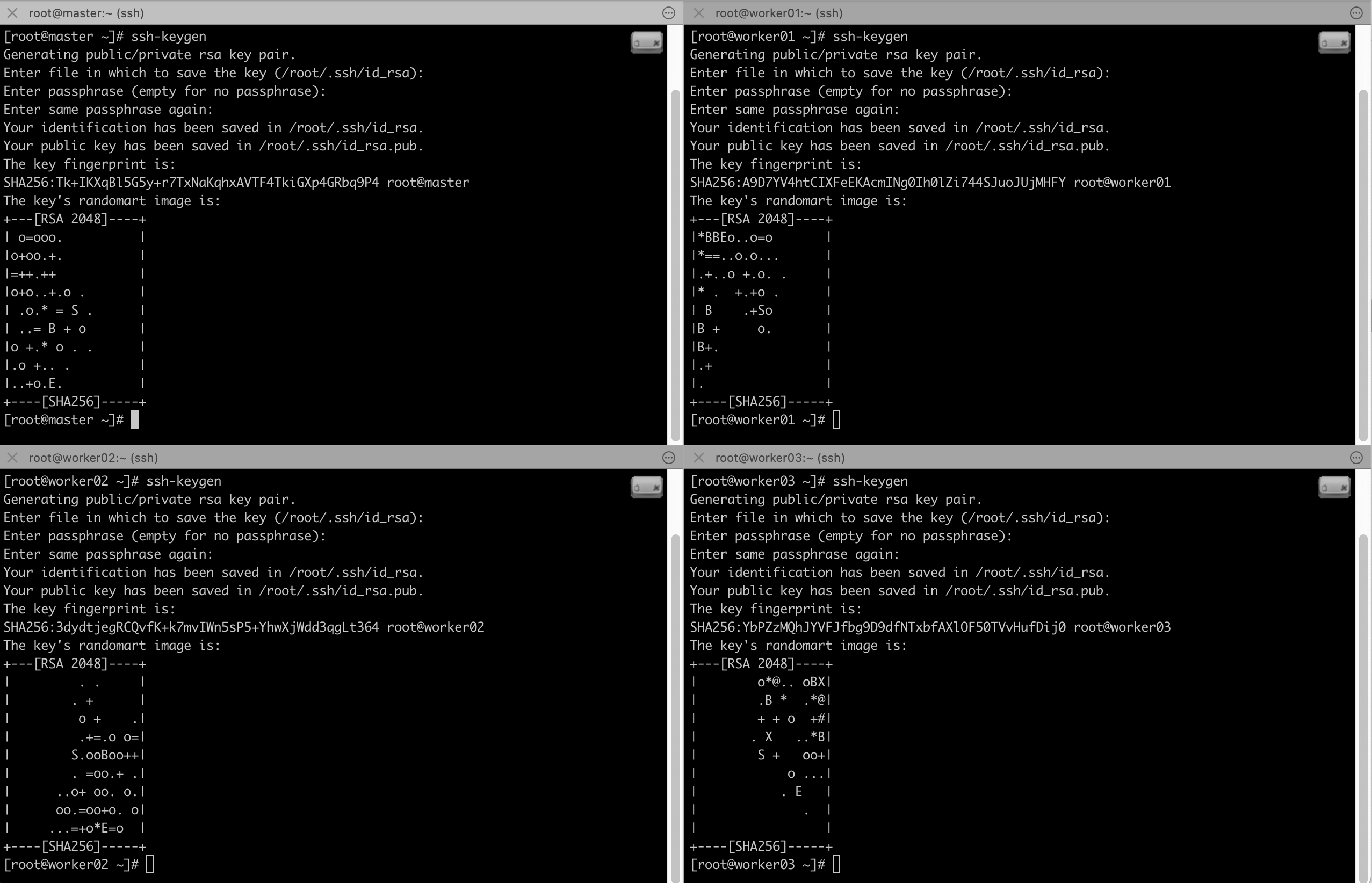
3) SSH 키 교환하기
이제 ssh키를 교환합니다. 네개의 노드에서 모두 동일하게 진행해주세요.
# ssh-copy-id root@master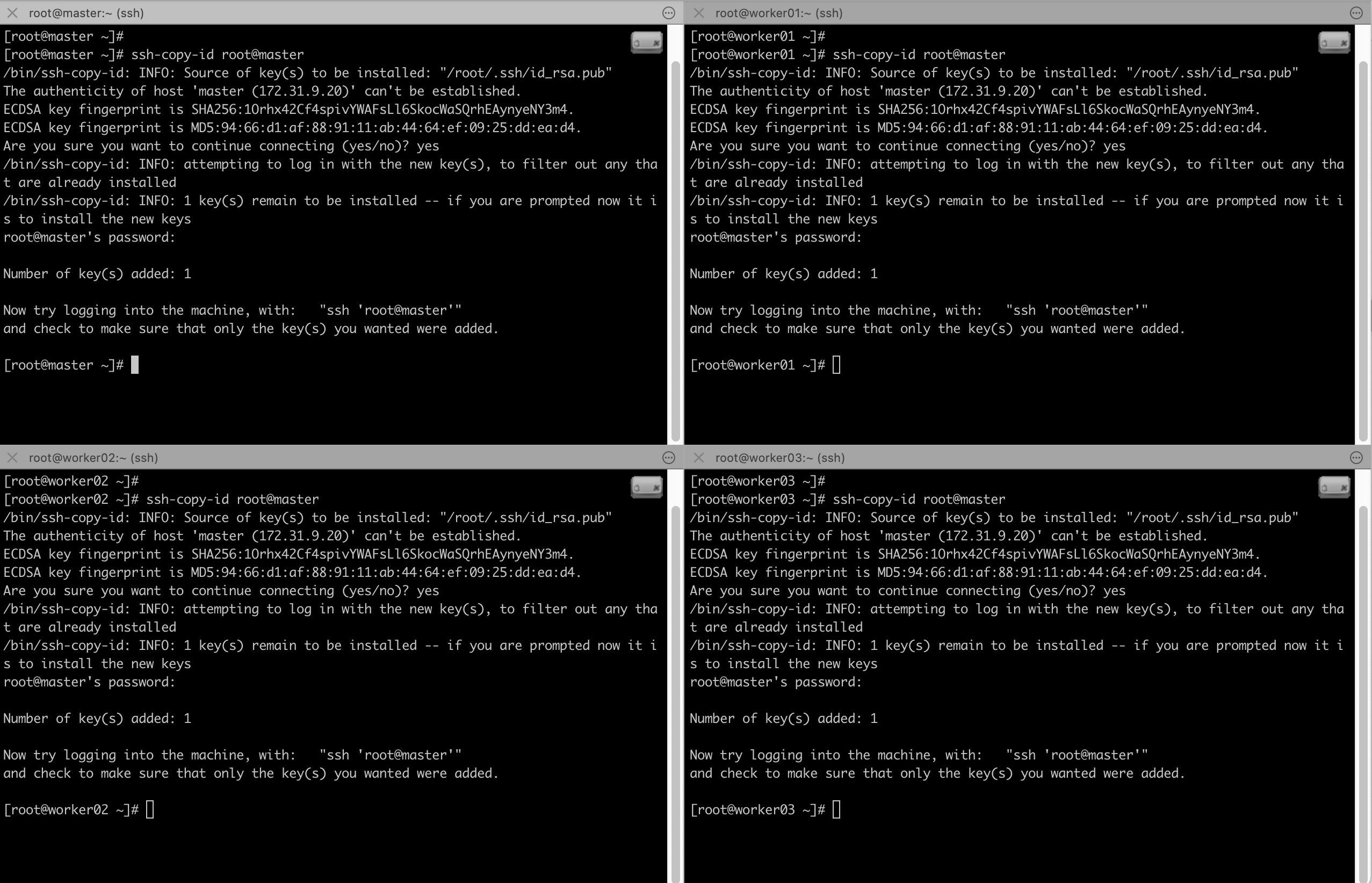
# ssh-copy-id root@worker01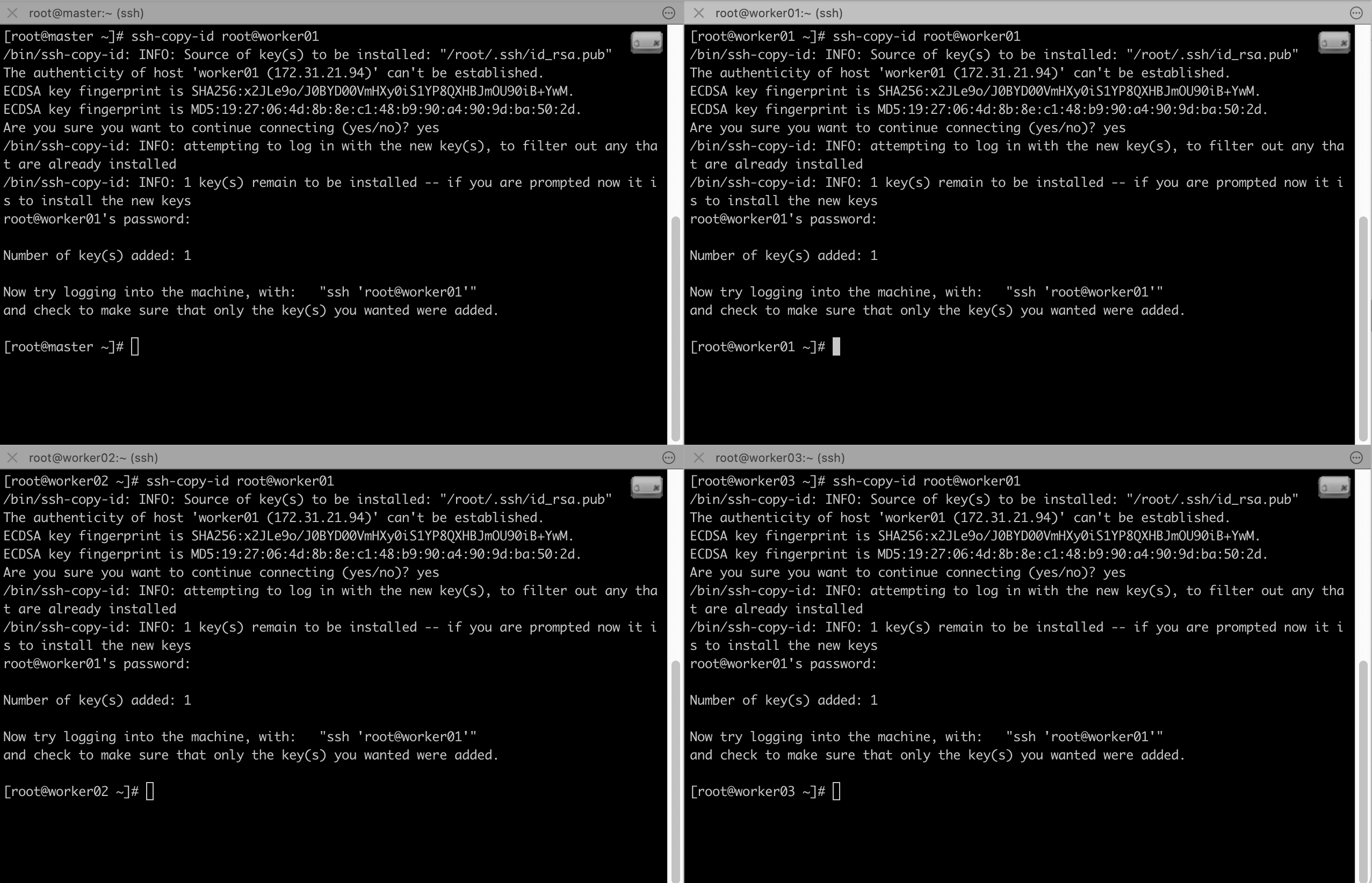
# ssh-copy-id root@worker02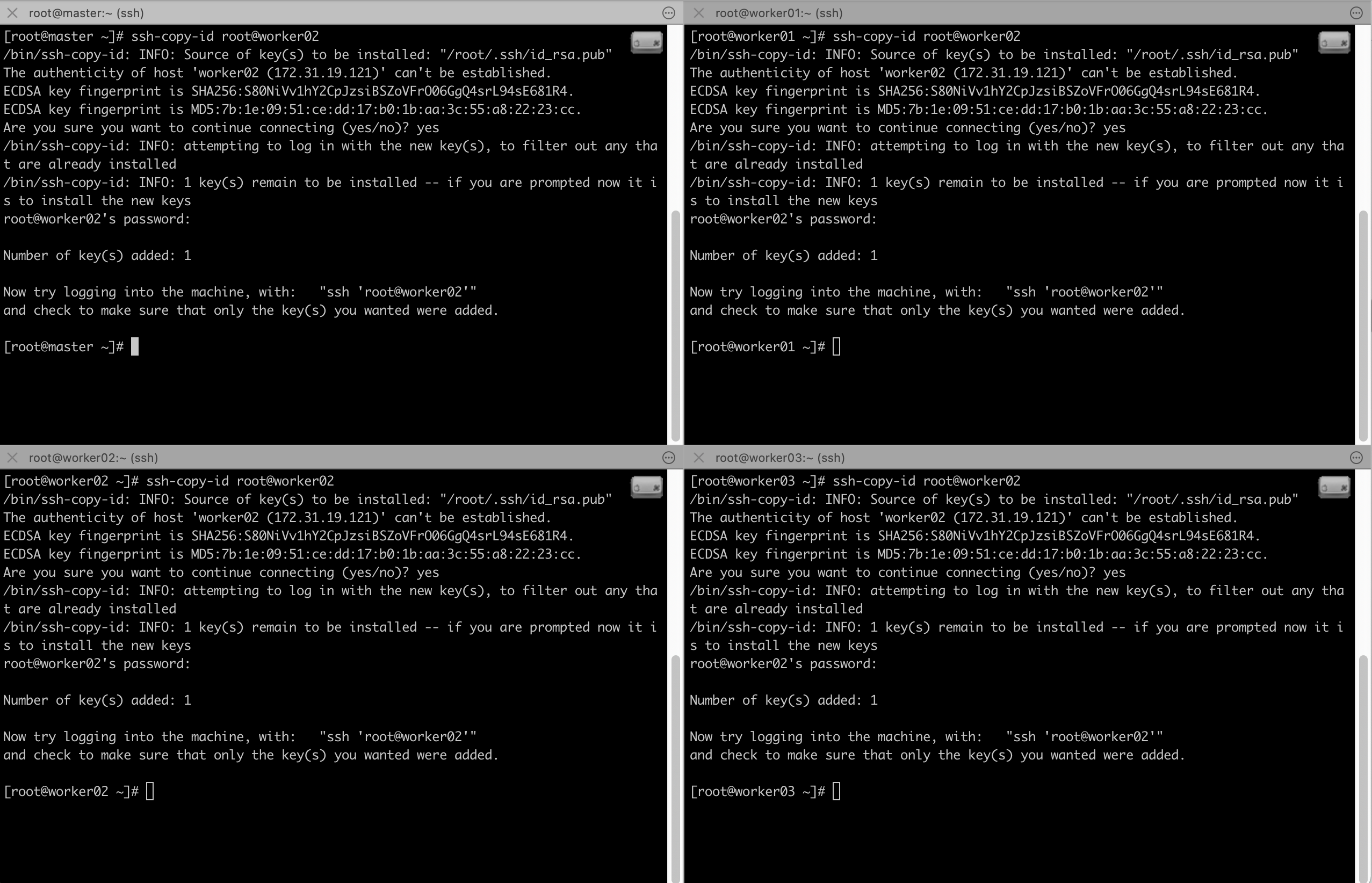
# ssh-copy-id root@worker03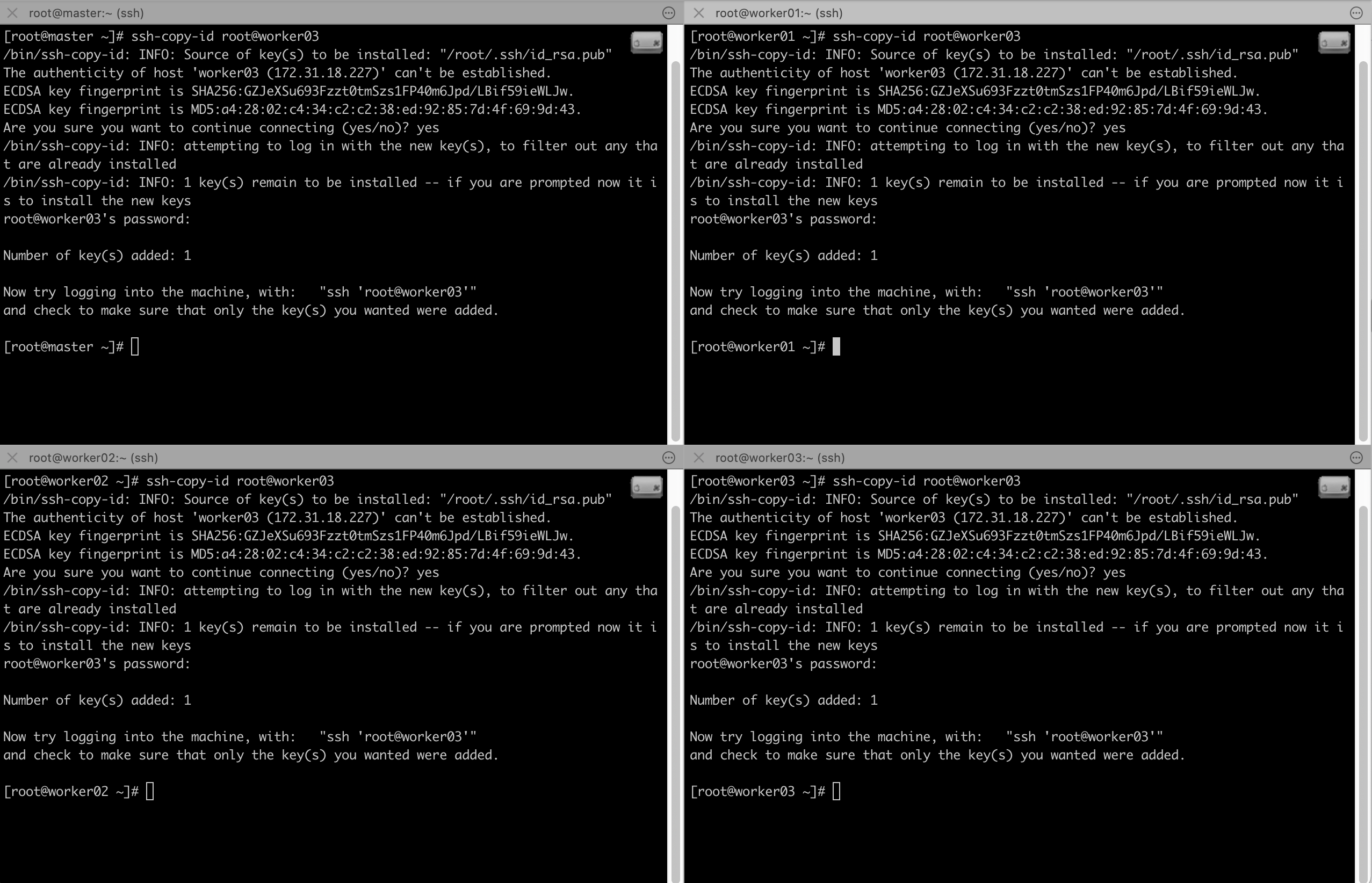
설정이 잘 되었다면 ssh worker01 이런식으로 접속했을때, 비밀번호를 묻지 않고 바로 로그인이 되어야합니다.
여기까지 진행 되었다면 ! 다음 단계로 진행해주세요.
4. HDFS 포멧하기
처음 디스크를 사용할때, OS에 맞게 파일 시스템을 포멧하는것 처럼, HDFS를 시작하기 전 포멧을 진행합니다 :)
NameNode 포멧은 Master 서버에서, DataNode 포멧은 Slave1, Slave2, Slave3 서버에서 진행합니다!
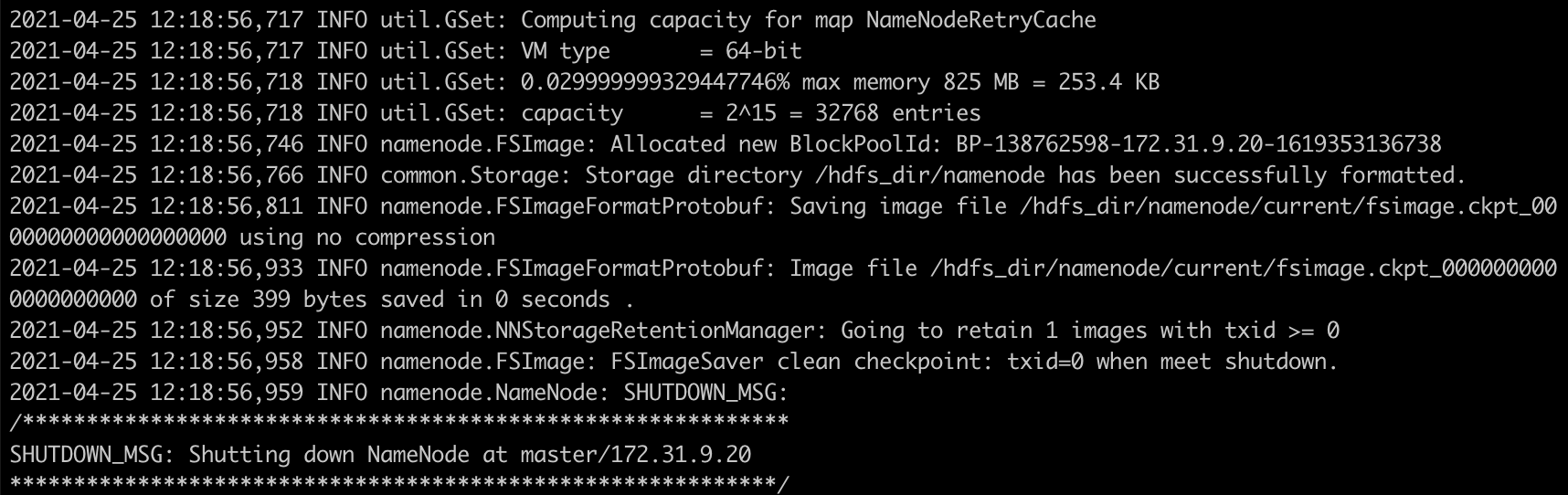
1) NameNode 포멧
마스터 노드와 Worker01노드에서 아래의 명령어를 실행하여 네임노드 포멧을 시작합니다.
(Worker01노드는 세컨더리 네임노드로 운영됩니다)
[root@master ~]# /usr/local/hadoop-3.3.0/bin/hdfs namenode -format /hdfs_dir
[root@worker01 ~]# /usr/local/hadoop-3.3.0/bin/hdfs namenode -format /hdfs_dir
(중간 생략)
2) DataNode 포멧
데이터 노드(worker01, worker02, worker03) 세 대에서도 아래의 명령어를 실행합니다.
[root@worker02 ~]# /usr/local/hadoop-3.3.0/bin/hdfs datanode -format /hdfs_dir/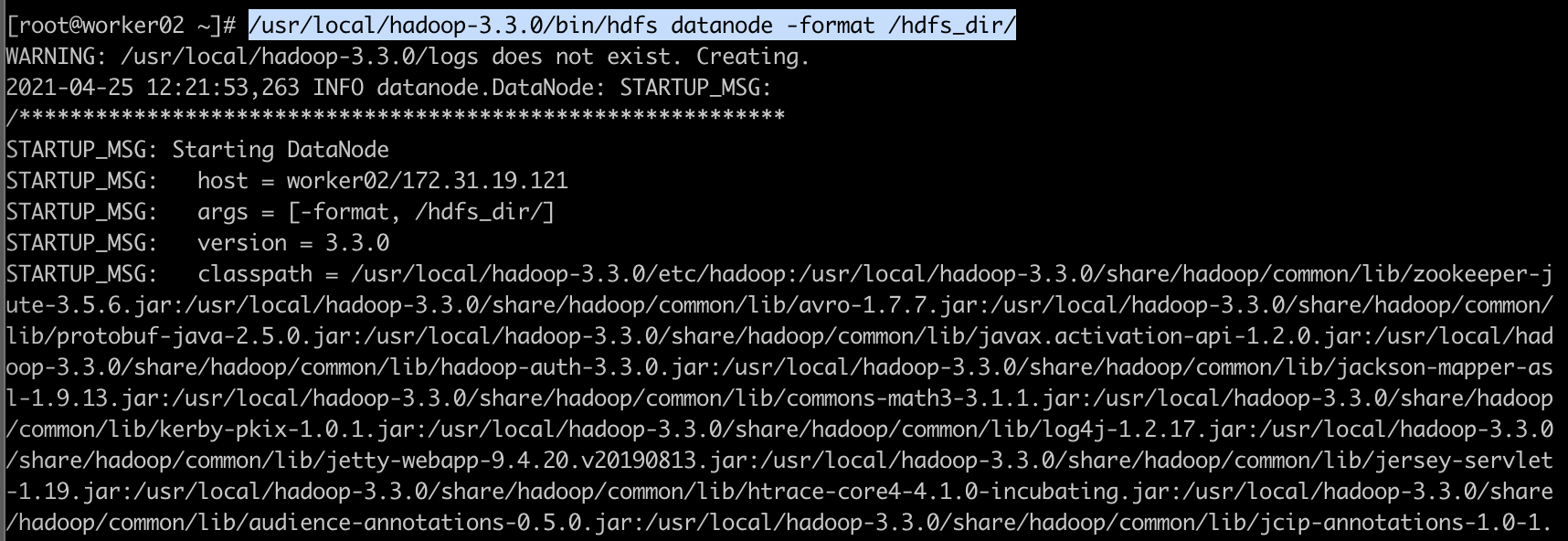
(중간 생략)
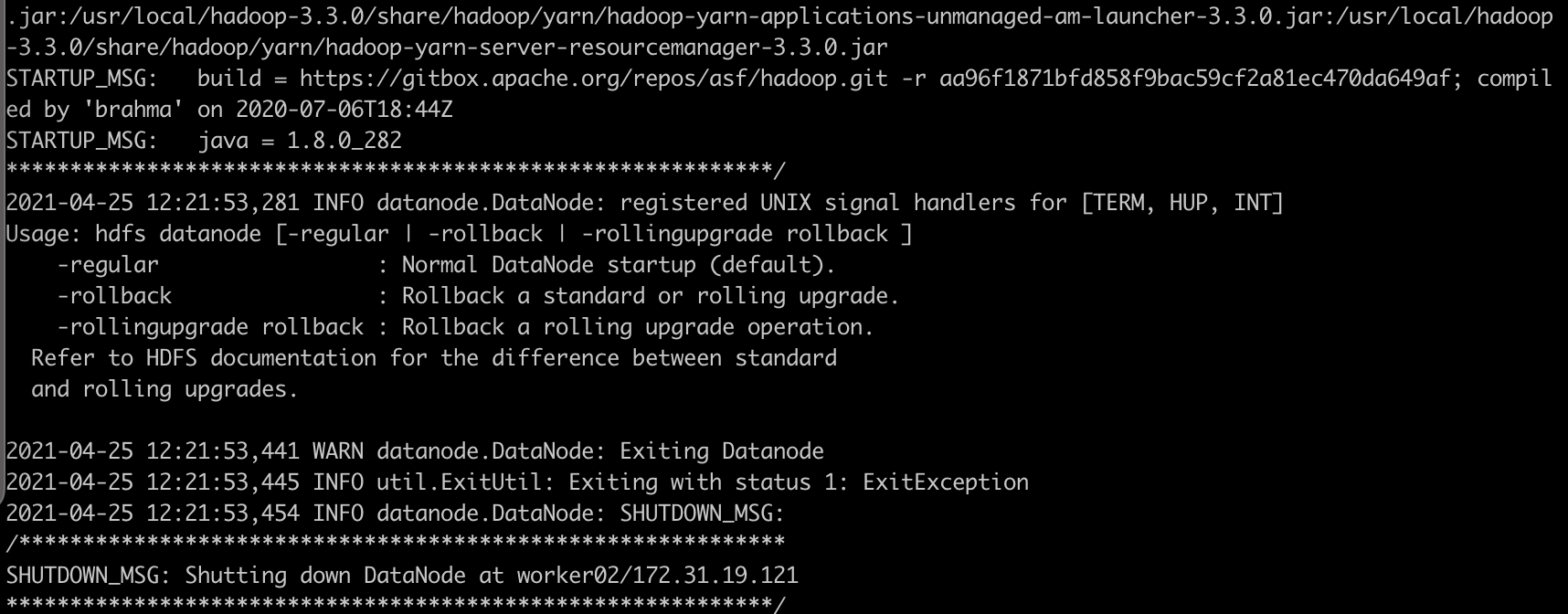
worker01, worker02, worker03 모두에서 똑같이 진행하셨다면, 다음 단계로 넘어갑니다!!
5. HDFS & YARN 시작하기
이제 HDFS&YARN을 실행하겠습니다.
※ Master 노드에서만 시작 명령어를 실행하면 됩니다.!👍🏻
실행을 위해서, 먼저 Master 노드에서 설정파일을 하나 수정합니다.
아래에서 수정할 workers 파일은 HDFS에서 실제 데이터를 저장할 데이터 노드를 지정하는 설정파일입니다.
[root@master ~]# vim /usr/local/hadoop-3.3.0/etc/hadoop/workers
worker01
worker02
worker03
데이터 노드 지정이 완료 되었다면, 이제 HDFS&YARN을 실행해봅시다!!
마스터 노드에서만 명령어를 실행해주면 됩니다.
[root@master ~]# /usr/local/hadoop-3.3.0/sbin/start-all.sh
jps 명령어로 HDFS & YARN이 잘 실행되었는지 확인 가능합니다.
[root@master ~]# jps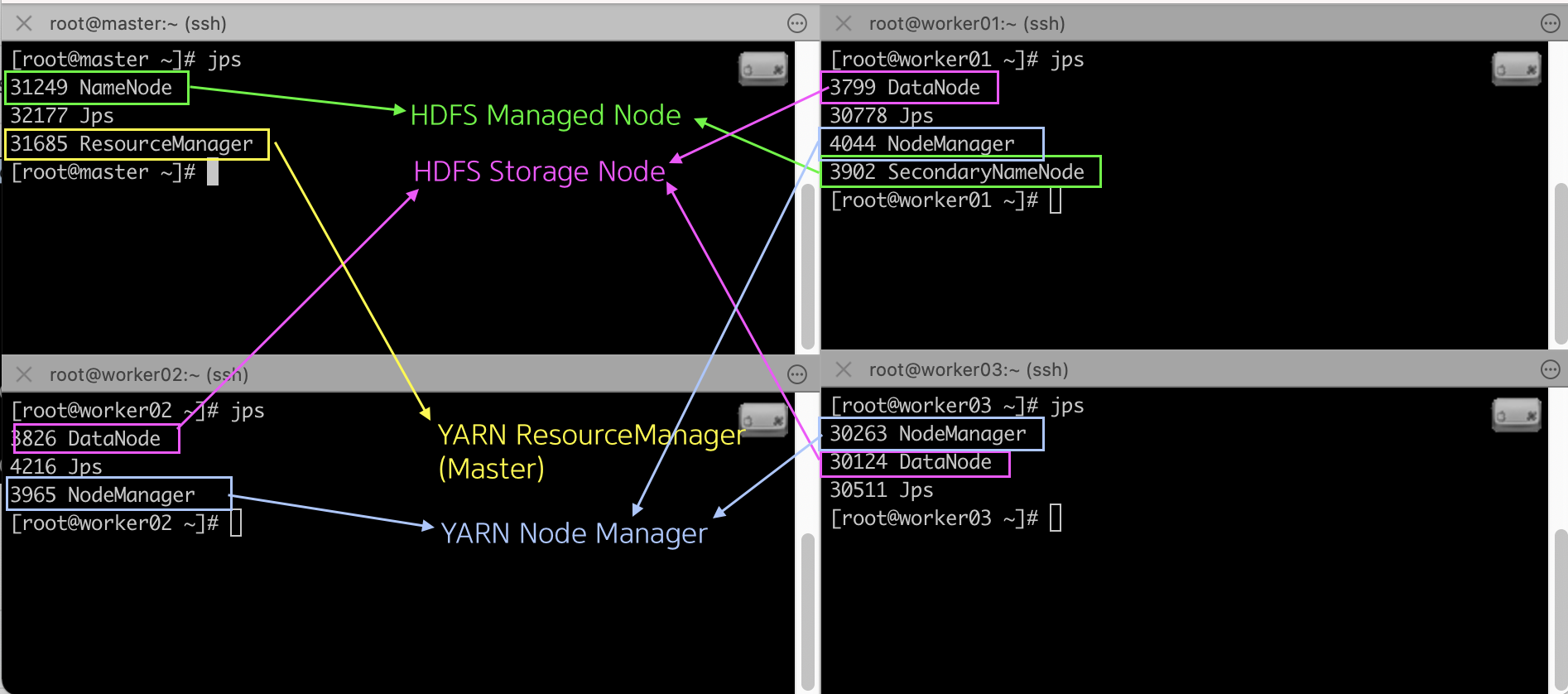
* HDFS GUI : http://<masterIP>:50070
* YARN GUI : http://<masterIP>:8080
6. Spark 시작하기
이제 Spark 을 실행하겠습니다.
※ Master 노드에서만 시작 명령어를 실행하면 됩니다.!👍🏻
실행을 위해서, Spark도 마찬가지로 Master 노드에서 설정파일을 하나 수정합니다.
아래에서 수정할 workers 파일은 클러스터 설정 파일입니다.
[root@master ~]# vim /usr/local/spark-3.1.1-bin-hadoop3.2/conf/workers
이제 실행시켜봅시다!
[root@master ~]# /usr/local/spark-3.1.1-bin-hadoop3.2/sbin/start-all.sh
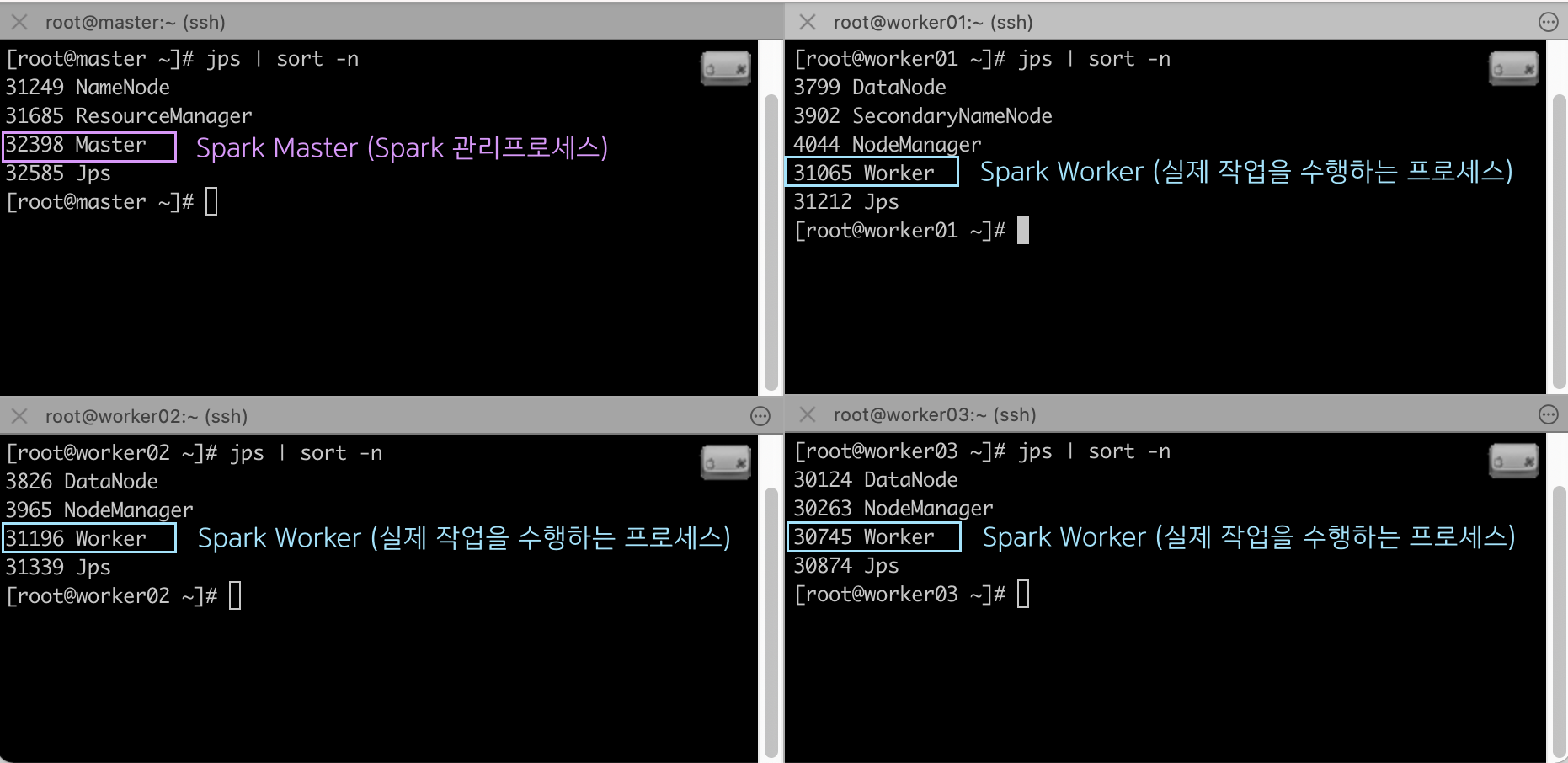
Spark 웹콘솔에 접속해보겠습니다.
3개의 워커노드가 보이네요 :)
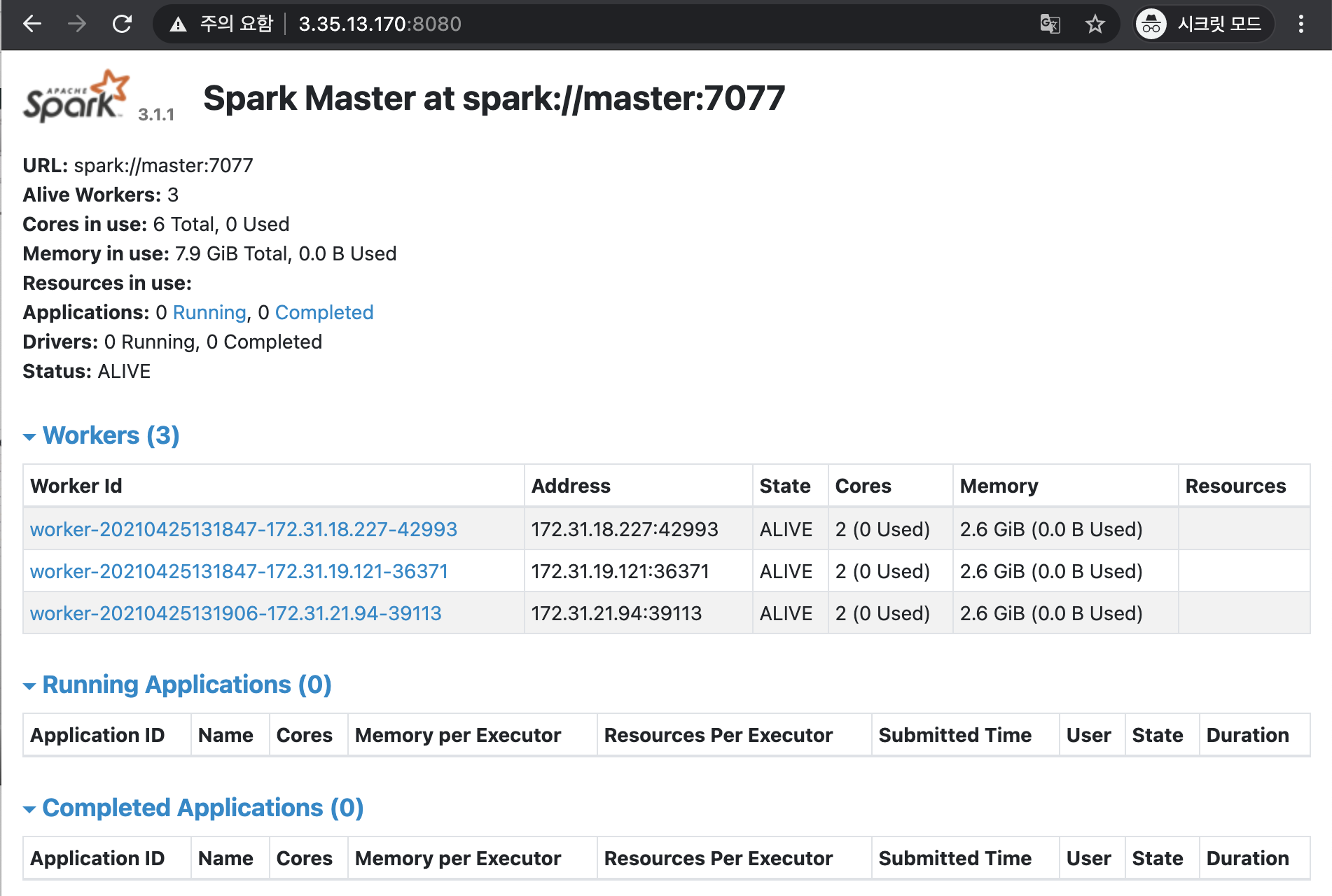
여기까지! 진행하면
HDFS + YARN + Spark 구성이 완료 되었습니다 :)
다음 포스팅에서는 Jupyter Notebook을 실행하고, 테스트 작업을 수행해보겠습니다!!
뿅!👻
다음포스팅으로 바로가기~👍🏻
Hadoop HDFS(3.3)+Spark(3.1.1)! 무작정 따라하기 #3