안녕하세요 😁😁😁😁!
저번 포스팅에는 하둡 HDFS 예전 버전 (2.0)을 설치했었습니다.
이번 포스팅에는 하둡HDFS 최신버전인 3.3를 설치하고, 그 위에 Spark도 함께 설치해보려고 합니다.
HDFS 3.3버전은 Java 1.8버전 이상이 필요합니다. ^.^
(Apache Hadoop 3.3 and upper supports Java 8 and Java 11)
이번 포스팅과 이어지는 포스팅들을 따라서 쭉 진행하면, HDFS+YARN+Spark 구성이 완성되고,
마지막으로는 주피터 노트북도 사용할 수 있도록 하려고 합니다.👍🏻
[설치해야할 라이브러리 목록]
1. Java 1.8
2. HDFS 3.3
3. Scala 2.13.5
4. Spark 3.1.1
자, 이제 한번 설치해봅시다!
1. EC2 인스턴스 생성하기!
이번 단계에서는 EC2 인스턴스를 생성합니다.
OS는 AmazonLinux2 를 사용할 예정입니다.!!!
AWS 웹 콘솔에 접속한 후 EC2서비스를 선택합니다.
맨 처음 화면에서 "인스턴스 시작" 버튼을 찾아 클릭합니다.
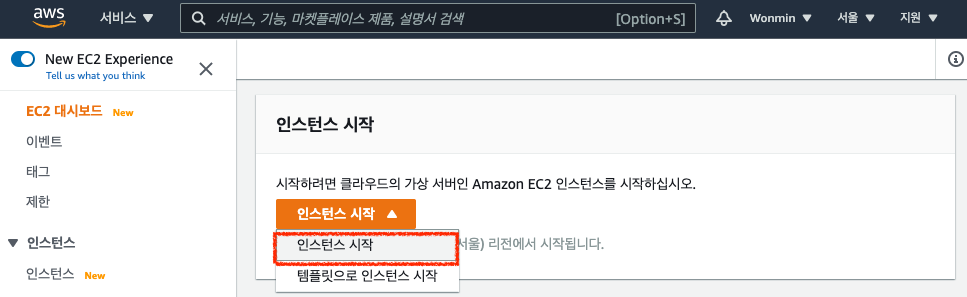
먼저, 1단계, AMI를 선택합니다.
저는 Amazon Linux2를 사용할 예정이므로, 첫페이지에서 바로 나오는 AMI를 선택해줍니다.
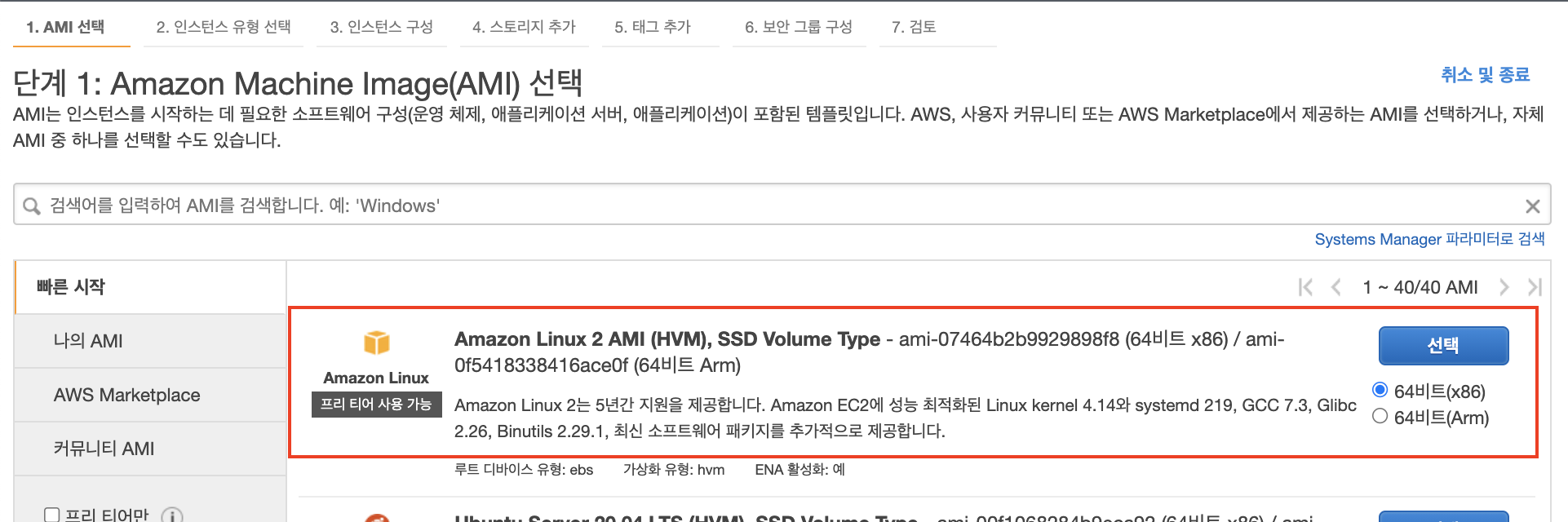
2단계, 인스턴스 유형을 선택합니다. 저는 c5.large을 선택한 후 "다음:인스턴스세부정보 구성"을 클릭합니다.
3단계, 인스턴스 구성입니다.
만약, VPC설정이나, EC2 Role 추가가 필요하다면 이 단계에서 진행해주셔야 합니다.
저는 별도로 설정할게 없기때문에 모두 기본으로 두고 다음:스토리지추가로 넘어갑니다.
4단계, 스토리지 추가 단계입니다.
저는 이 단계에서 50GiB gp3 스토리지를 추가했습니다. (HDFS 스토리지가 될 영역입니다.)
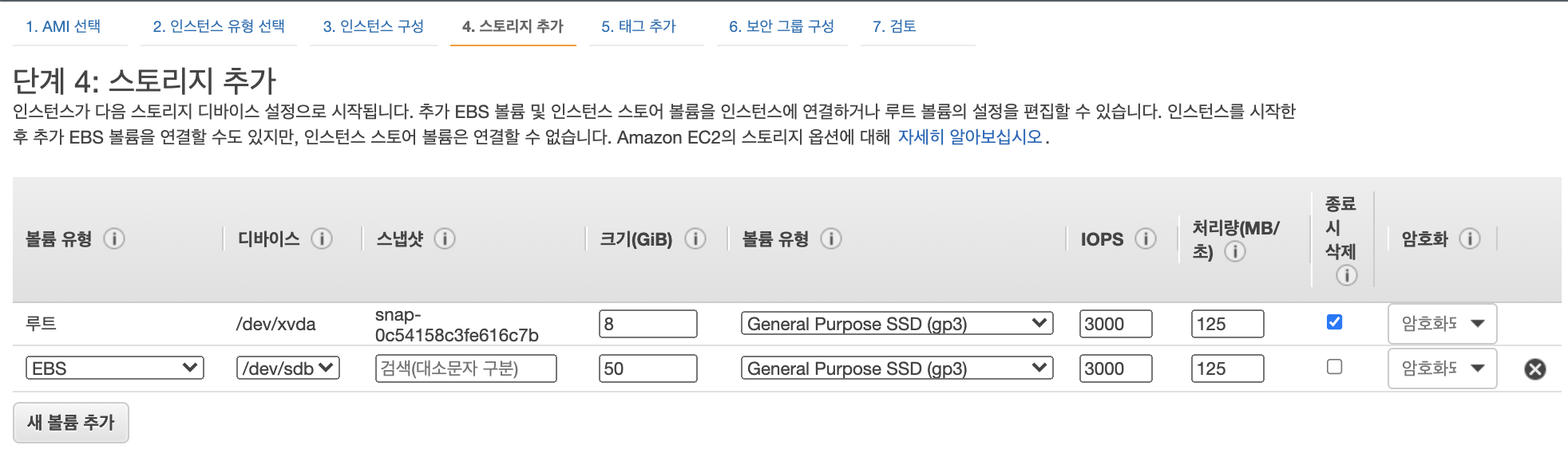
추가하셨다면 이제 "검토 및 시작"을 클릭합니다.
7단계, 검토부분입니다. 아래까지 쭉 검토한 후 시작하기를 클릭합니다.
키페어 팝업창에서 가지고있는 키 페어를 선택하거나 새 키페어를 생성합니다.

몇 분 후 인스턴스를 사용할 수 있습니다.
인스턴스 목록에서 새로 생성된 인스턴스를 확인하고 이름을 HDFS with Spark 으로 변경하였습니다.
그리고 퍼블릭IP주소를 확인해줍시다!
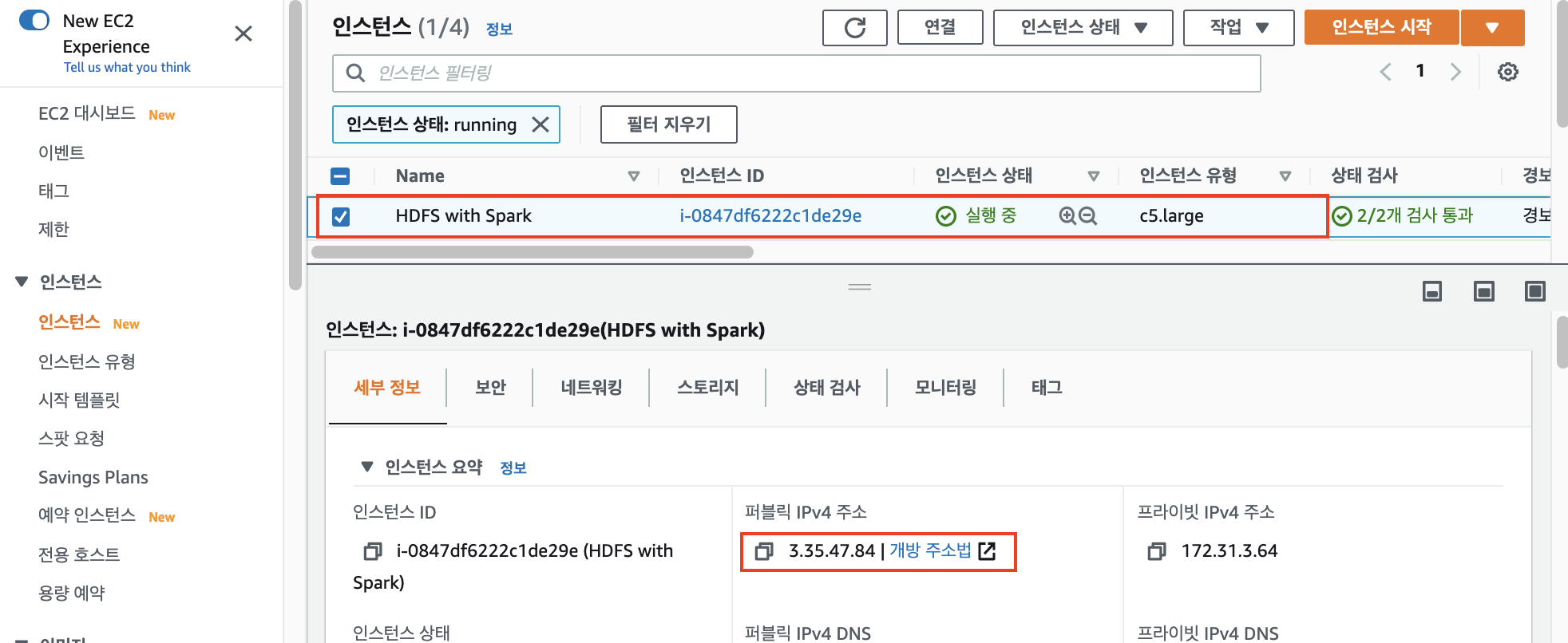
이제 이 인스턴스에 SSH로 접속합니다.
ssh -i <키페어경로> ec2-user@<퍼블릭IP>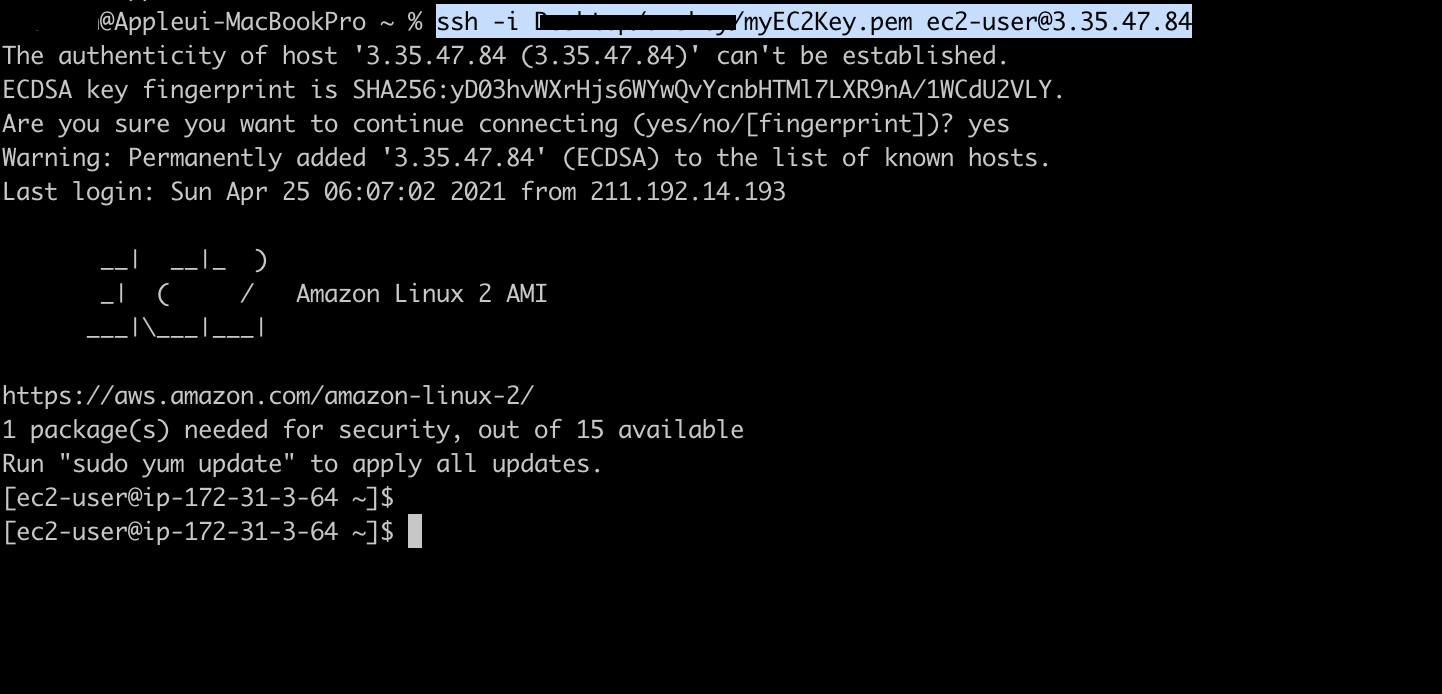
인스턴스에 접속까지 했으면, 이번 단계는 여기서 완료 되었습니다 :)
다음 단계로 넘어갑시다!
2. HDFS 스토리지가 될 디스크 포멧하기!
위에서 50GiB짜리 EBS를 별도로 추가했습니다.
lsblk 명령어로 해당 디스크를 확인할 수 있습니다.
[ec2-user@ip-172-31-3-64 install_dir]$ lsblk
이 디스크를 xfs로 포멧해줍니다!!
[ec2-user@ip-172-31-3-64 install_dir]$ sudo mkfs.xfs /dev/nvme1n1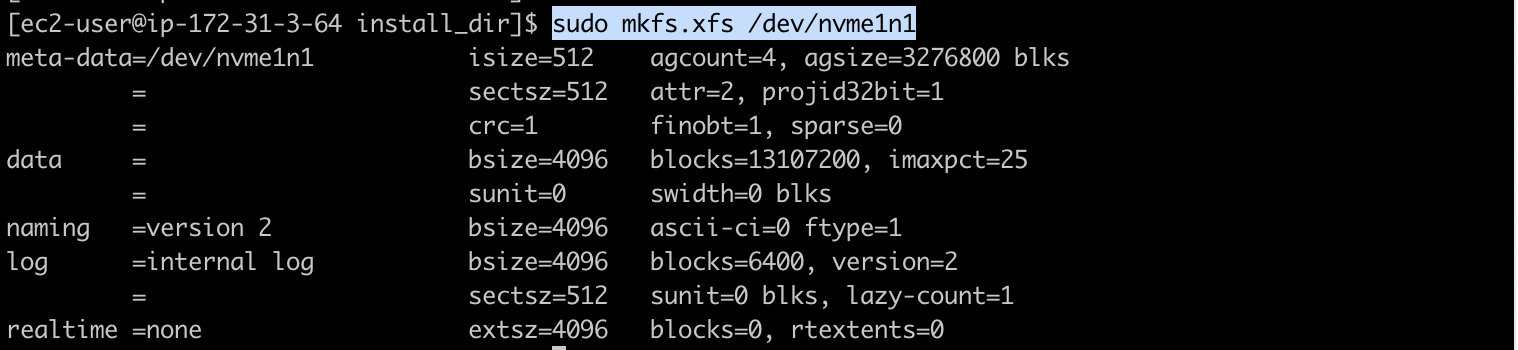
이 디스크를 마운트할 경로를 생성하고 fstab 설정파일을 수정합니다.
※ mount명령어로 마운트 할 수 있지만, 재부팅등으로 마운트가 해제될 수 있기때문에 fstab 파일을 수정하여 마운트 경로를 지정합니다. (mount명령어로 설정 = 일시적으로 마운트, fstab = OS부팅 시 마운트)
※ 모든 설정이 끝난 후 이 인스턴스를 복제하여 사용할 예정입니다.
※주의 : 실 운영환경에서는 디스크의 UUID를 확인하여 UUID기준으로 마운트 하세요. (UUID 확인 명령어 : ls -l /dev/disk/by-uuid | grep xvda)
[ec2-user@ip-172-31-3-64 install_dir]$ sudo vi /etc/fstab
------- 추가 -------------------------------------------------------------
/dev/nvme1n1 /hdfs_dir xfs defaults 1 1
-------------------------------------------------------------------------
그리고 "/hdfs_dir" 디렉터리를 생성한 후 mount -a 명령어를 실행하여, 마운트를 해줍니다.
[ec2-user@ip-172-31-3-64 install_dir]$ sudo mkdir /hdfs_dir
[ec2-user@ip-172-31-3-64 install_dir]$ sudo mount -a
[ec2-user@ip-172-31-3-64 install_dir]$ df -h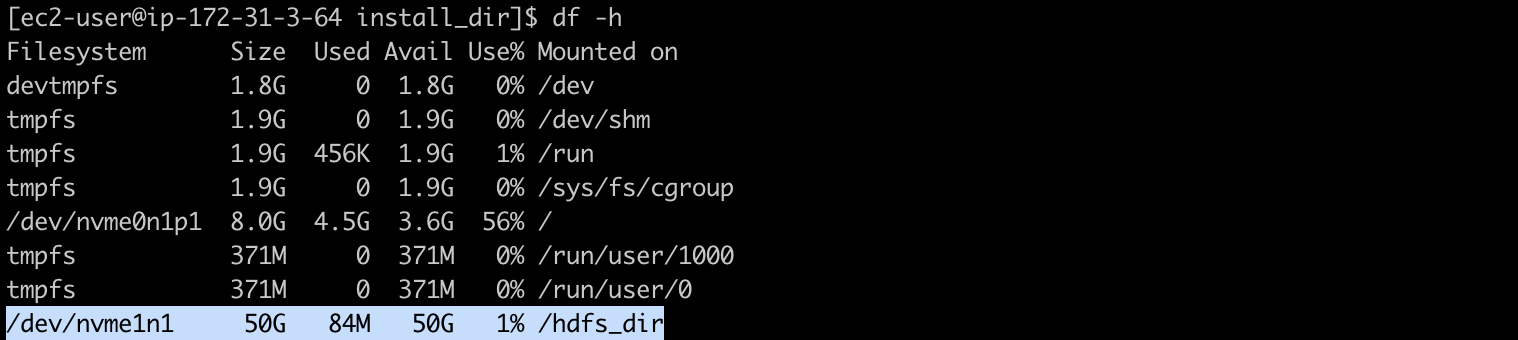
이렇게 /dev/nvme1n1 디스크가 /hdfs_dir 경로에 마운트되있는걸 확인 했다면, 이 단계는 완료되었습니다!
다음 단계로 넘어갑니다.
3. 소프트웨어 설치하기 (java, HDFS, Scala, Spark)
1) yum update
먼저 시작하기 전에,OS의 최신 업데이트를 적용하기 위해 "yum update"를 해줍니다.
[ec2-user@ip-172-31-3-64 ~]$ sudo yum update -y
2) Java 1.8 설치하기
java는 yum 레포지토리에서 사용이 가능하며, 아래 search 명령어로 확인 가능합니다.
설치 가능한 패키지 목록중에 java-1.8.0-openjdk를 설치하겠습니다.
[ec2-user@ip-172-31-3-64 ~]$ sudo yum search java 1.8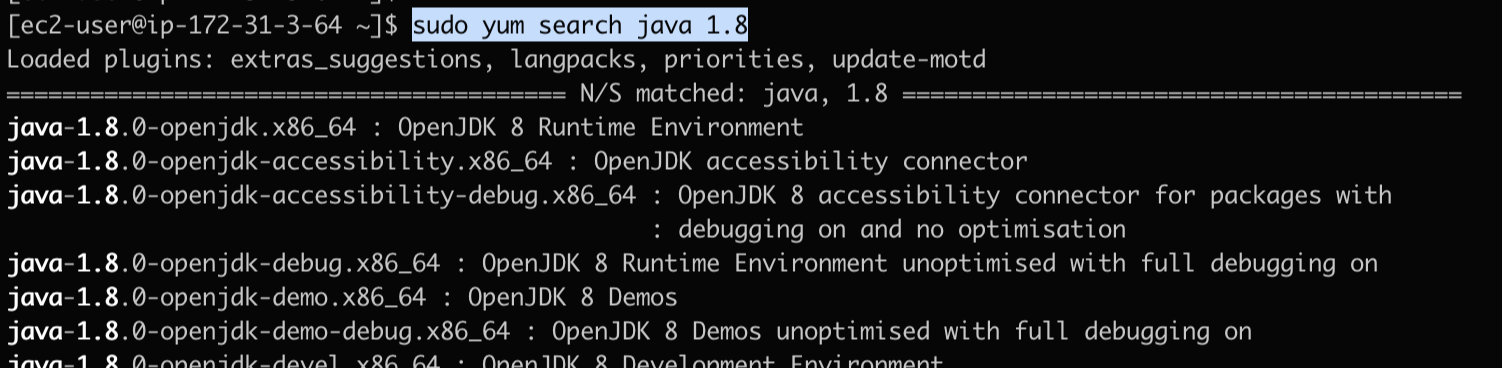
아래 명령어로 java-1.8.0을 설치합니다.
[ec2-user@ip-172-31-3-64 ~]$ sudo yum install java-1.8.0-openjdk -y
설치가 완료 되었다면, java -version 명령어로 설치된 버전을 확인합니다.
1.8버전이 설치되었다면 정상적으로 설치가 완료된 것 입니다!
[ec2-user@ip-172-31-3-64 ~]$ java -version
3) Hadoop 3.3 설치하기
설치를 진행하기 전 설치파일을 위한 별도의 경로 /install_dir 디렉터리를 생성합니다.
그리고 이 경로에 hadoop 3.3 바이너리 파일을 다운받습니다. (다운로드)
[ec2-user@ip-172-31-3-64 ~]$ sudo mkdir /install_dir
[ec2-user@ip-172-31-3-64 ~]$ cd /install_dir/
[ec2-user@ip-172-31-3-64 install_dir]$ sudo wget https://mirror.navercorp.com/apache/hadoop/common/hadoop-3.3.0/hadoop-3.3.0.tar.gz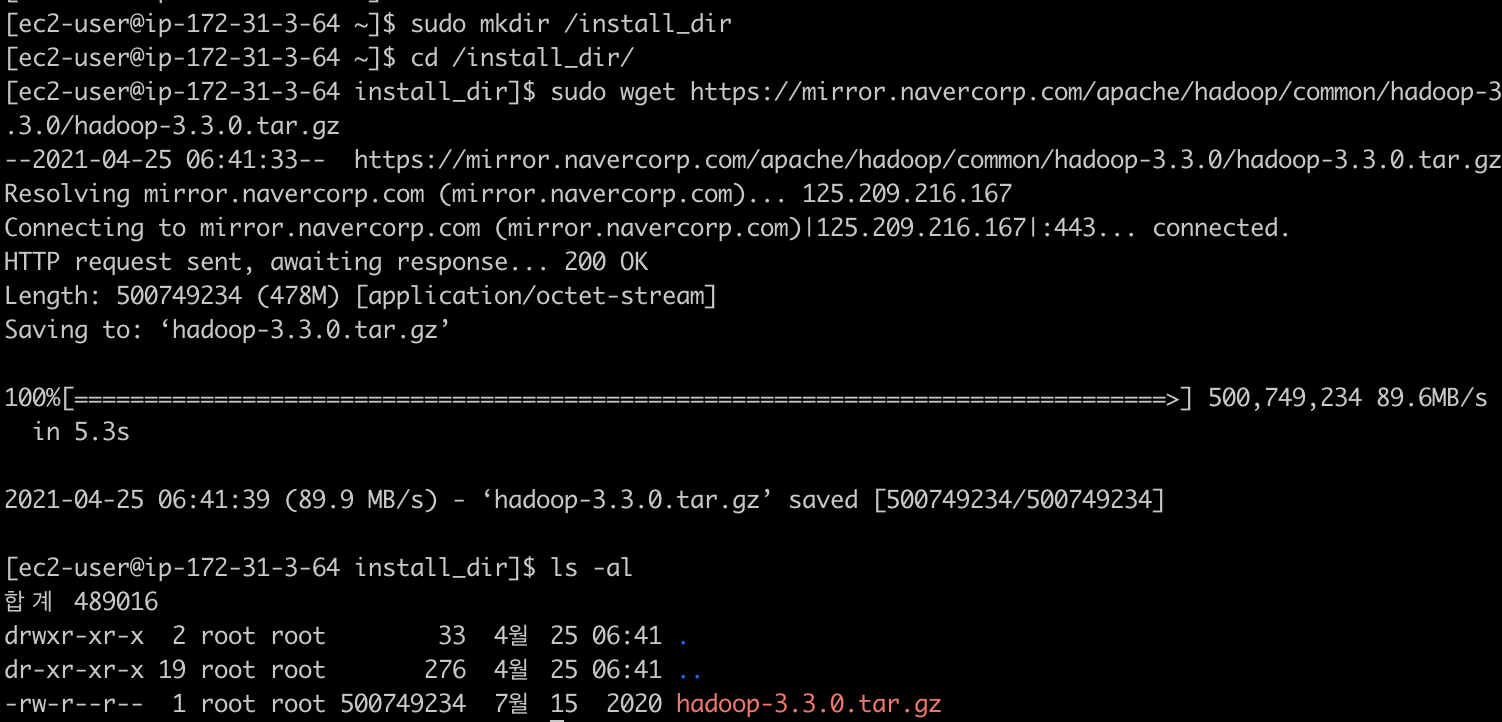
잘 다운받아졌는지 확인해봅니다.
[ec2-user@ip-172-31-3-64 install_dir]$ ls -al
이제 이 압축파일을 사용할 수 있도록 /usr/local 아래 경로에 압축을 해제한 후에 경로를 확인합니다.
[ec2-user@ip-172-31-3-64 install_dir]$ sudo tar -zxvf hadoop-3.3.0.tar.gz -C /usr/local/
[ec2-user@ip-172-31-3-64 install_dir]$ ls -al /usr/local/hadoop-3.3.0/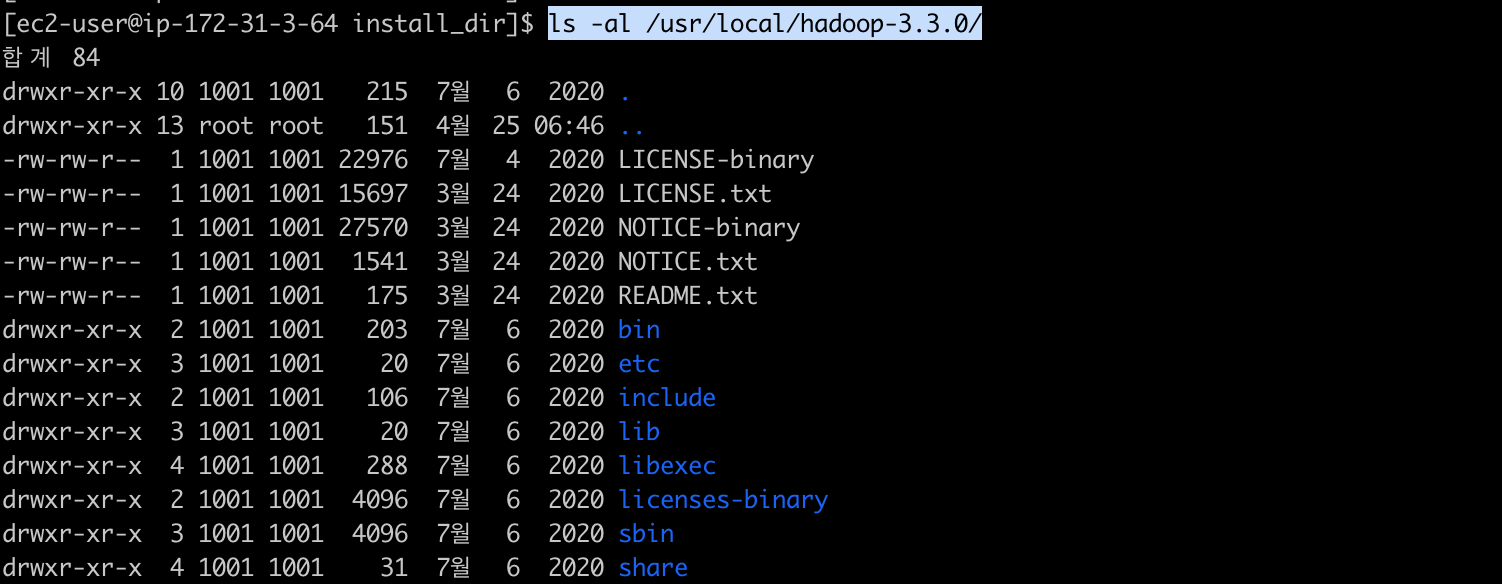
그리고 이 경로의 모든 디렉터리/파일의 소유권을 변경해줍니다.
[ec2-user@ip-172-31-3-64 install_dir]$ sudo chown root:root -R /usr/local/hadoop-3.3.0/
[ec2-user@ip-172-31-3-64 install_dir]$ ls -al /usr/local/hadoop-3.3.0/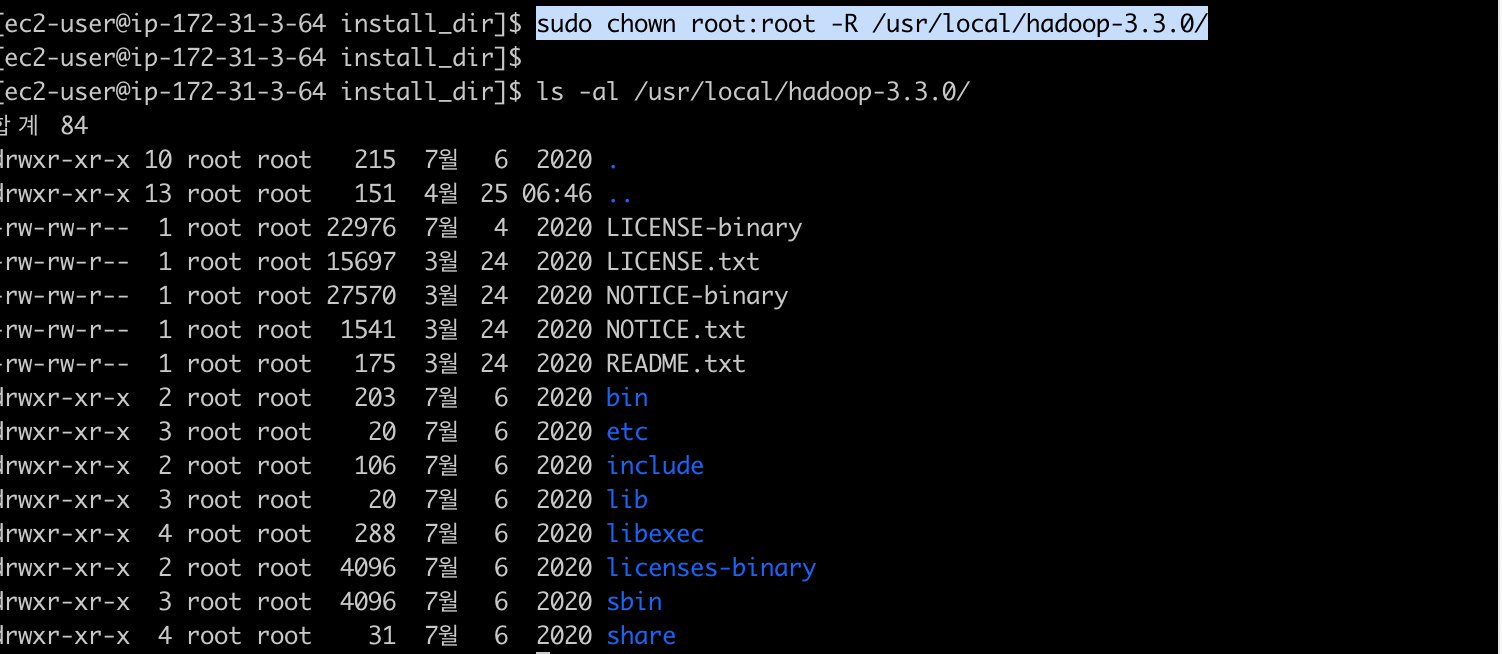
4) Scala 2.13.5 설치하기
Scala 2.13.5 를 설치합니다. (Scala 2.13.5는 Java 1.8버전이 반드시 필요합니다!!)
[ec2-user@ip-172-31-3-64 install_dir]$ sudo wget https://downloads.lightbend.com/scala/2.13.5/scala-2.13.5.tgz
[ec2-user@ip-172-31-3-64 install_dir]$ ls -al
다운받은 파일의 압축을 /usr/local 경로에 풀어줍니다.
그리고, 마찬가지로 파일/디렉터리의 소유권을 변경해줍시다.
[ec2-user@ip-172-31-3-64 install_dir]$ sudo tar -xzvf scala-2.13.5.tgz -C /usr/local/
[ec2-user@ip-172-31-3-64 install_dir]$ sudo chown -R root:root /usr/local/scala-2.13.5/Scala의 설치와 설정이 잘 되었는지 확인하기 위해서 아래와 같이 스칼라를 실행해볼 수 있습니다.
[ec2-user@ip-172-31-3-64 install_dir]$ /usr/local/scala-2.13.5/bin/scala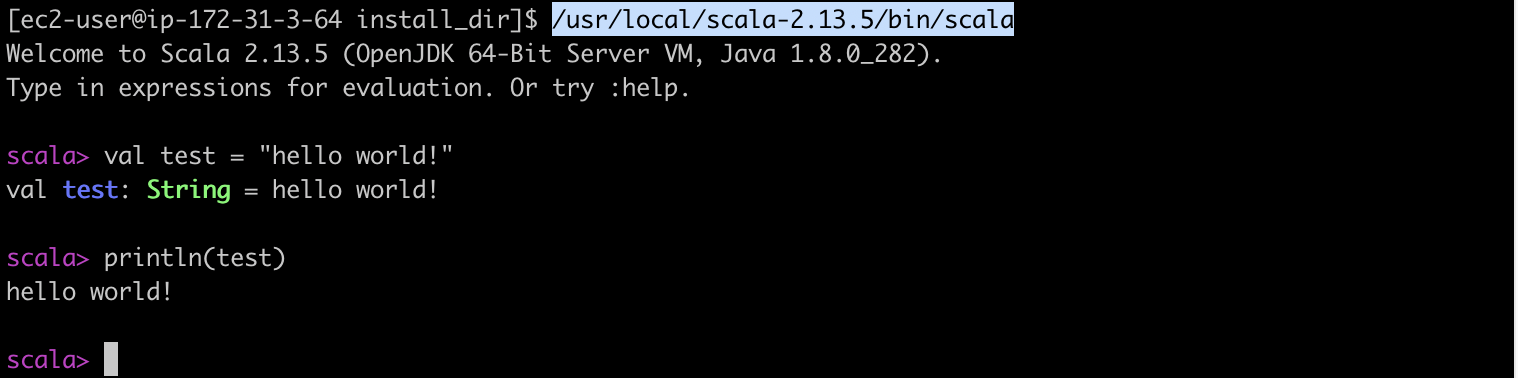
스칼라가 잘 설치 되었다면, 위의 캡쳐와 같이 실행되는것을 확인할수 있습니다.
5) Spark 3.1.1 설치하기
이제 마지막 설치 단계입니다. (다운로드)
아래 명령어를 복붙해서 파일을 다운로드 해주세요!
[ec2-user@ip-172-31-3-64 install_dir]$ sudo wget https://mirror.navercorp.com/apache/spark/spark-3.1.1/spark-3.1.1-bin-hadoop3.2.tgz
그리고 다운받은 파일을 /usr/local 경로에 압축을 해제하고, 소유권을 변경해줍니다.
[ec2-user@ip-172-31-3-64 install_dir]$ sudo tar -xzvf spark-3.1.1-bin-hadoop3.2.tgz -C /usr/local/
[ec2-user@ip-172-31-3-64 install_dir]$ sudo chown -R root:root /usr/local/spark-3.1.1-bin-hadoop3.2/잘 설치가 되었는지 확인하기 위해 아래 명령어를 실행하여 Spark-Shell을 실행해봅니다.
뒤에서는 Spark Cluster 모드로 실행될 예정입니다 :)
[ec2-user@ip-172-31-3-64 install_dir]$ /usr/local/spark-3.1.1-bin-hadoop3.2/bin/spark-shell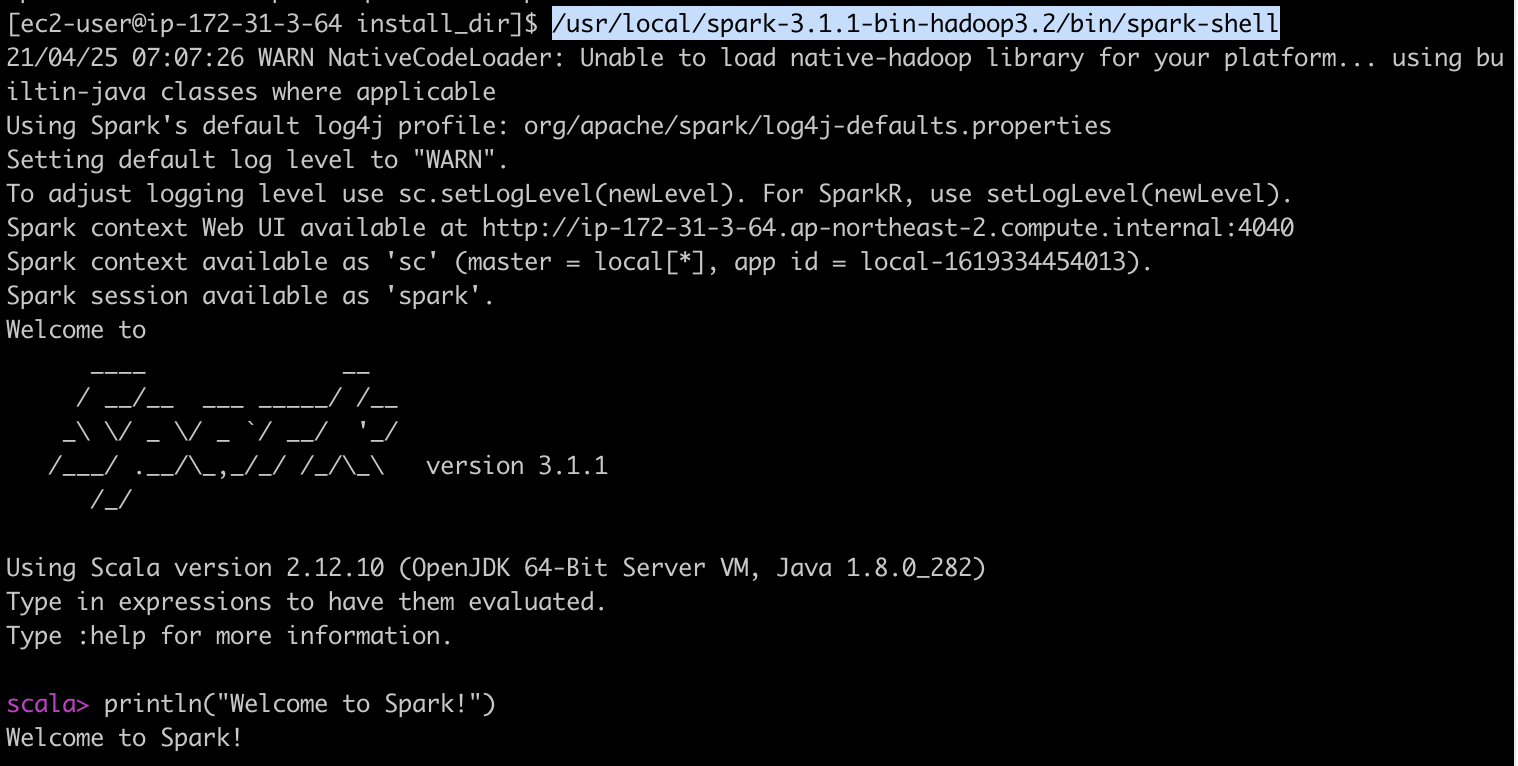
여기까지 완료 되었으면 모든 소프트웨어를 설치 완료했습니다.
다음 단계에서 환경변수 설정과 설정파일들을 수정하겠습니다!
4. 환경변수 설정 및 HDFS 설정파일 수정하기!
1) 환경변수
하둡과 스파크를 실행할때 환경변수를 잘못 설정하면 오류가 오지게 난다요....ㅜ...주의해서 설정하세요...😂😂😂
/etc/profile을 열고, 아래와 같이 환경변수를 추가합니다.
[ec2-user@ip-172-31-3-64 install_dir]$ sudo vim /etc/profile
export JAVA_HOME=/usr/lib/jvm/jre-1.8.0-openjdk-1.8.0.282.b08-1.amzn2.0.1.x86_64
export HADOOP_HOME=/usr/local/hadoop-3.3.0
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_HOME=/usr/local/spark-3.1.1-bin-hadoop3.2
2) 하둡 설정파일
- 하둡 설정파일 경로: /usr/local/hadoop-3.3.0/etc/hadoop/ *.xml
- core-site.xml : 공통 설정
- hdfs * .xml : HDFS 설정
- mapred * .xml: Mapreduce 설정
- yarn * .xml : yarn 설정
2-1) core-site.xml
하둡 시스템 설정 파일로, 로그파일, 네트워크 튜닝, I/O튜닝, 파일시스템튜닝, 압축 등 시스템 설정 파일입니다.
HDFS와 맵리듀스에서 공통적으로 사용할 환경정보를 입력하게 되며, core-default.xml이 기본 값이며, core-site.xml에 설정값이 없는 경우 기본 값을 그대로 사용합니다.
[ec2-user@ip-172-31-3-64 install_dir]$ sudo vim /usr/local/hadoop-3.3.0/etc/hadoop/core-site.xml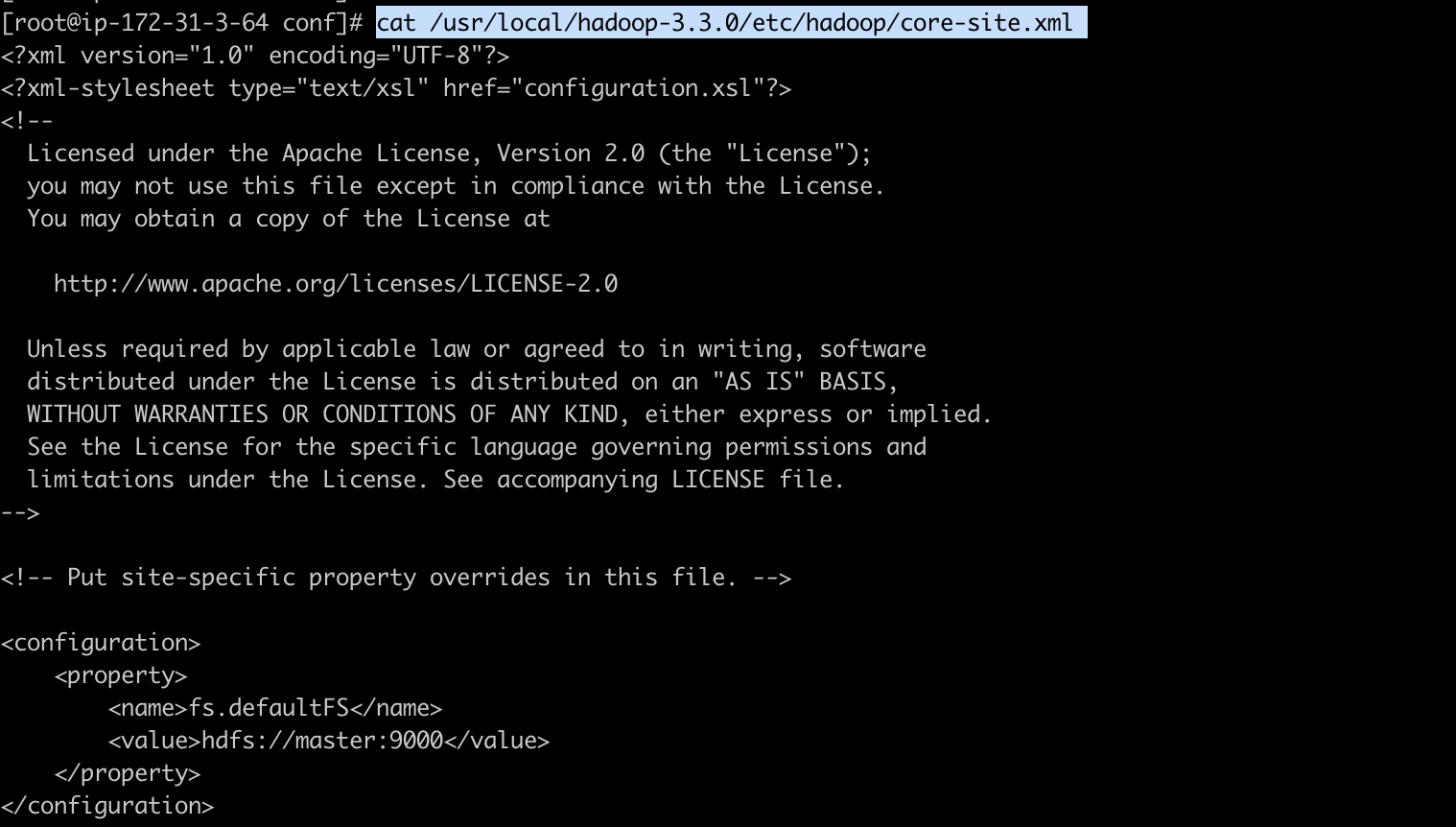
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
2-2) hdfs-site.xml
HDFS에서 사용할 환경정보를 설정합니다. hdfs-default.xml이 기본 값이며, hdfs-site.xml에 설정값이 없는 경우 기본 값을 그대로 사용합니다.
[ec2-user@ip-172-31-3-64 install_dir]$ sudo vim /usr/local/hadoop-3.3.0/etc/hadoop/hdfs-site.xml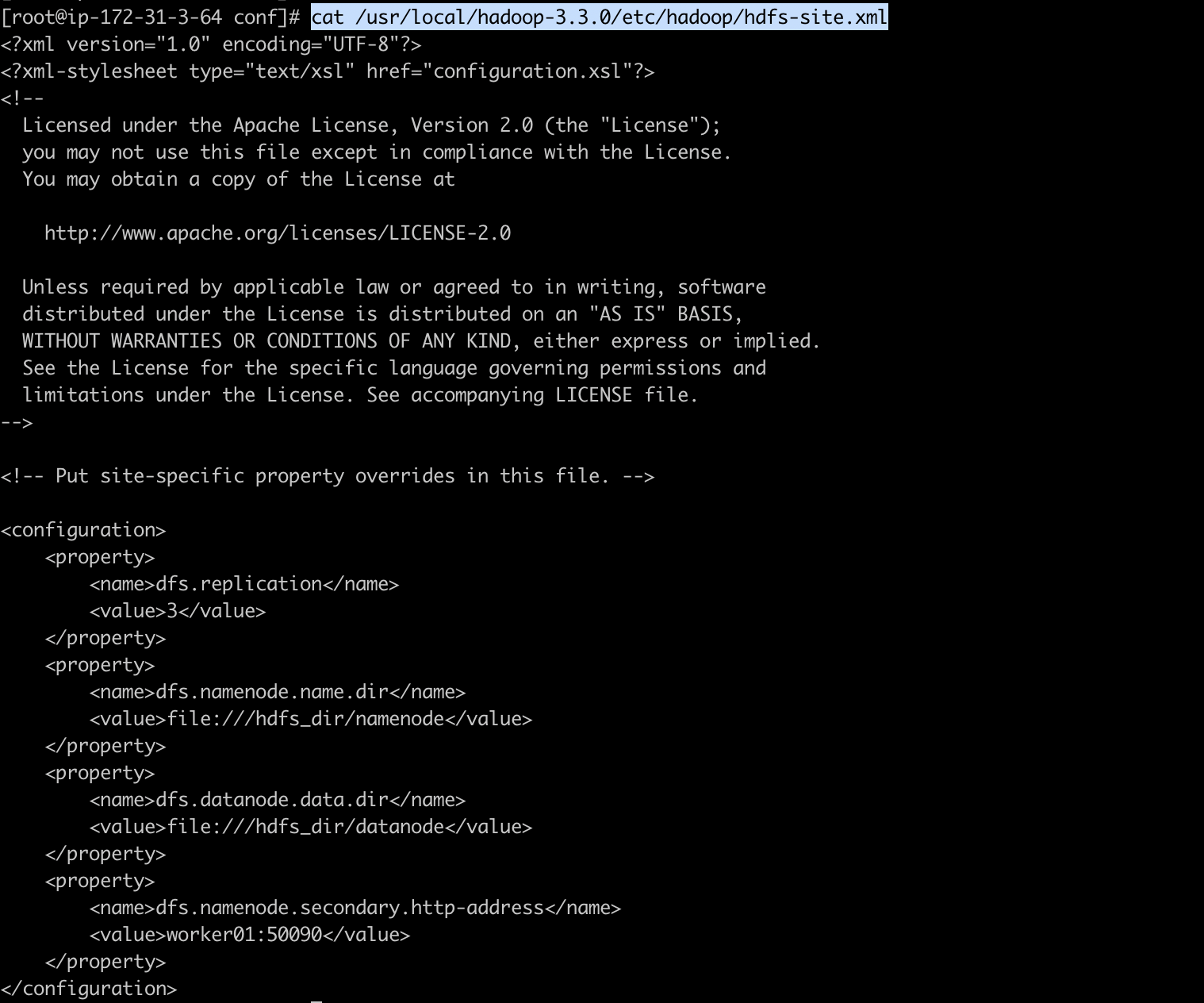
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///hdfs_dir/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///hdfs_dir/datanode</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>worker01:50090</value>
</property>
</configuration>
2-3) yarn-site.xml
Resource Manager 및 Node Manager에 대한 구성을 정의합니다.
[ec2-user@ip-172-31-3-64 install_dir]$ sudo vim /usr/local/hadoop-3.3.0/etc/hadoop/yarn-site.xml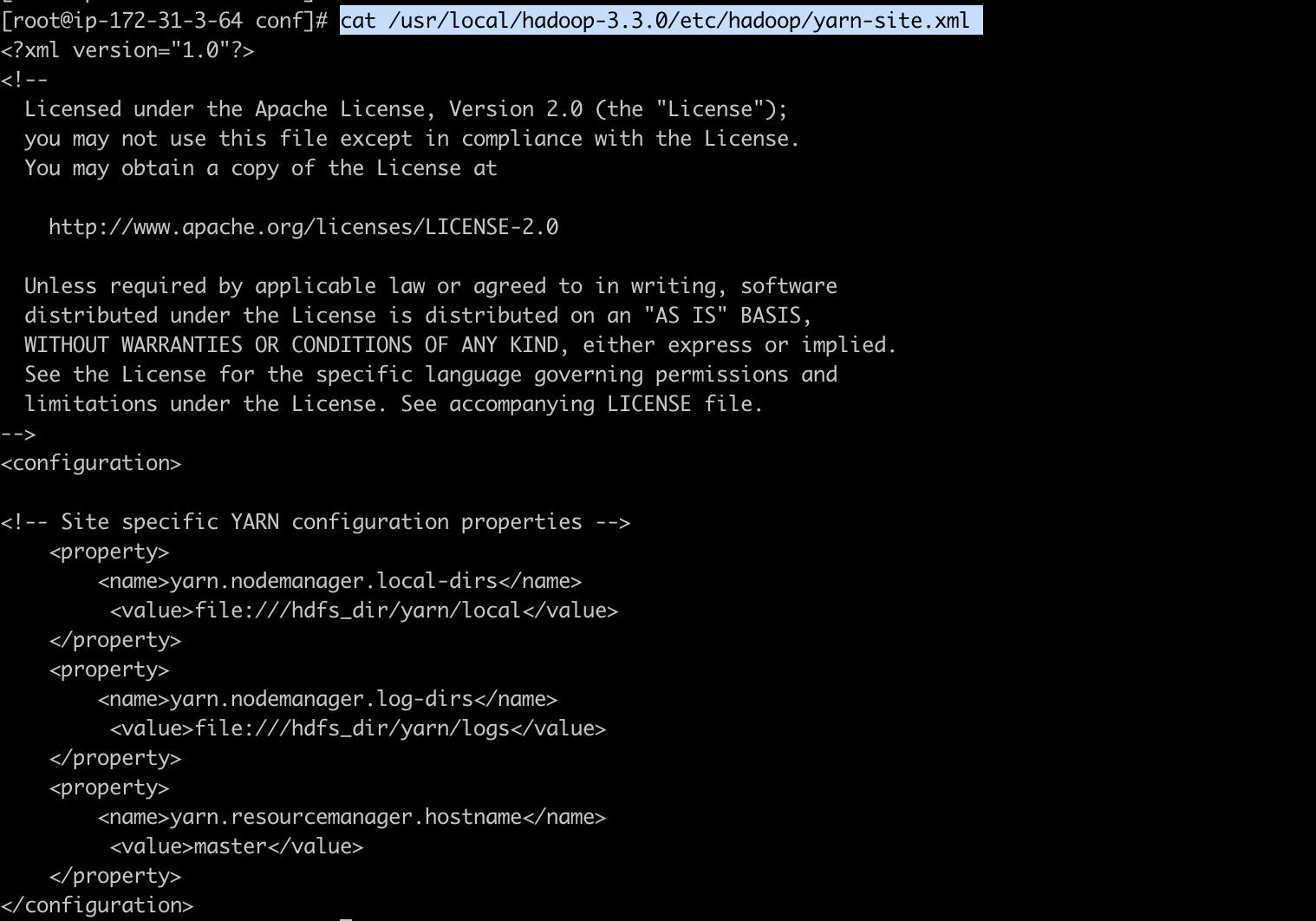
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>file:///hdfs_dir/yarn/local</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>file:///hdfs_dir/yarn/logs</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
</configuration>
2-4) mapred-site.xml
MapReduce 어플리케이션 설정 파일입니다.
[ec2-user@ip-172-31-3-64 install_dir]$ sudo vim /usr/local/hadoop-3.3.0/etc/hadoop/mapred-site.xml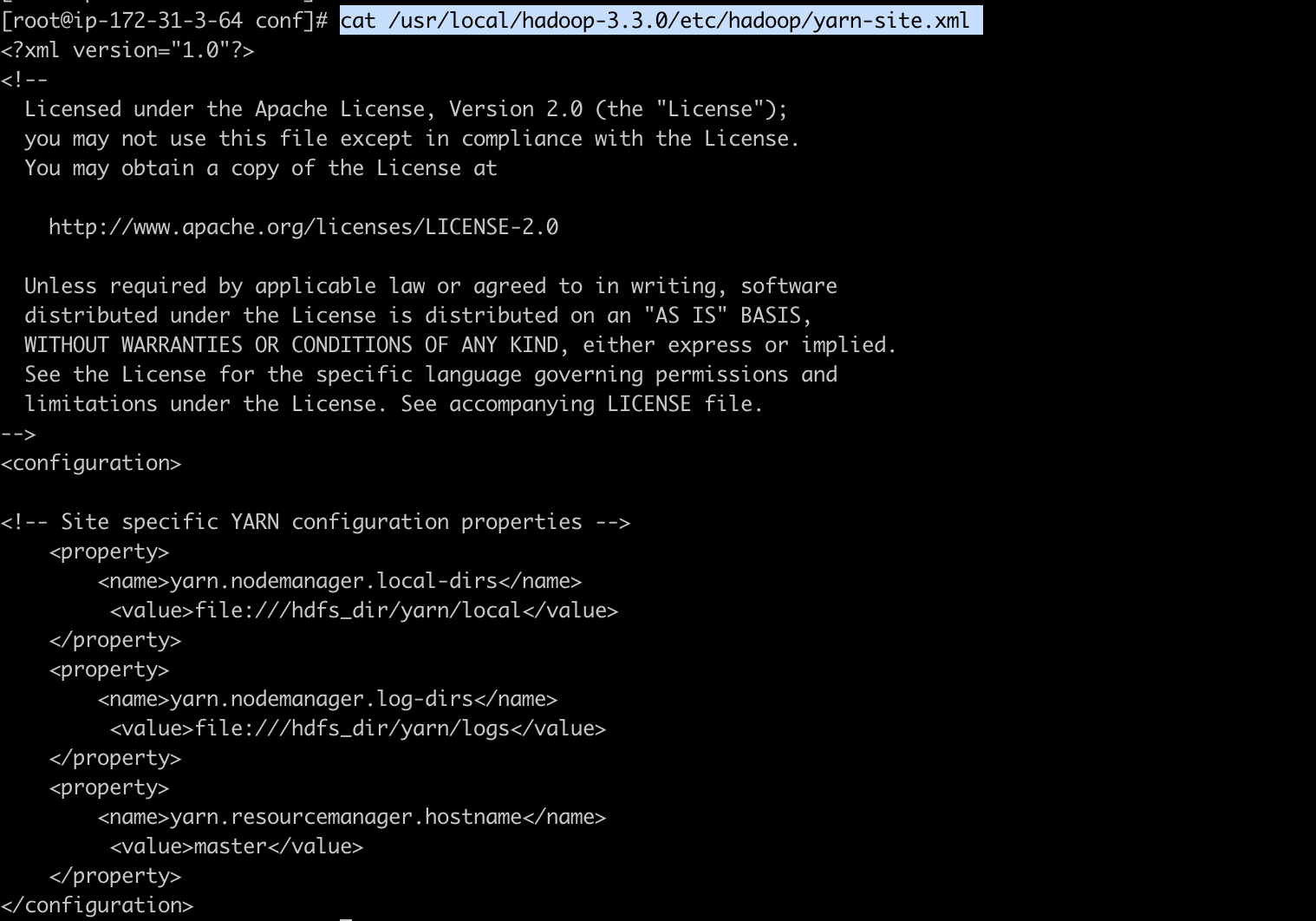
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
2-5) hadoop-env.sh
hadoop 환경설정 파일에 java 설정을 해줍니다. 이부분도 빠졌을 경우에 오류가 나오더라고요 ㅠㅠ
[ec2-user@ip-172-31-3-64 install_dir]$ sudo vim /usr/local/hadoop-3.3.0/etc/hadoop/hadoop-env.sh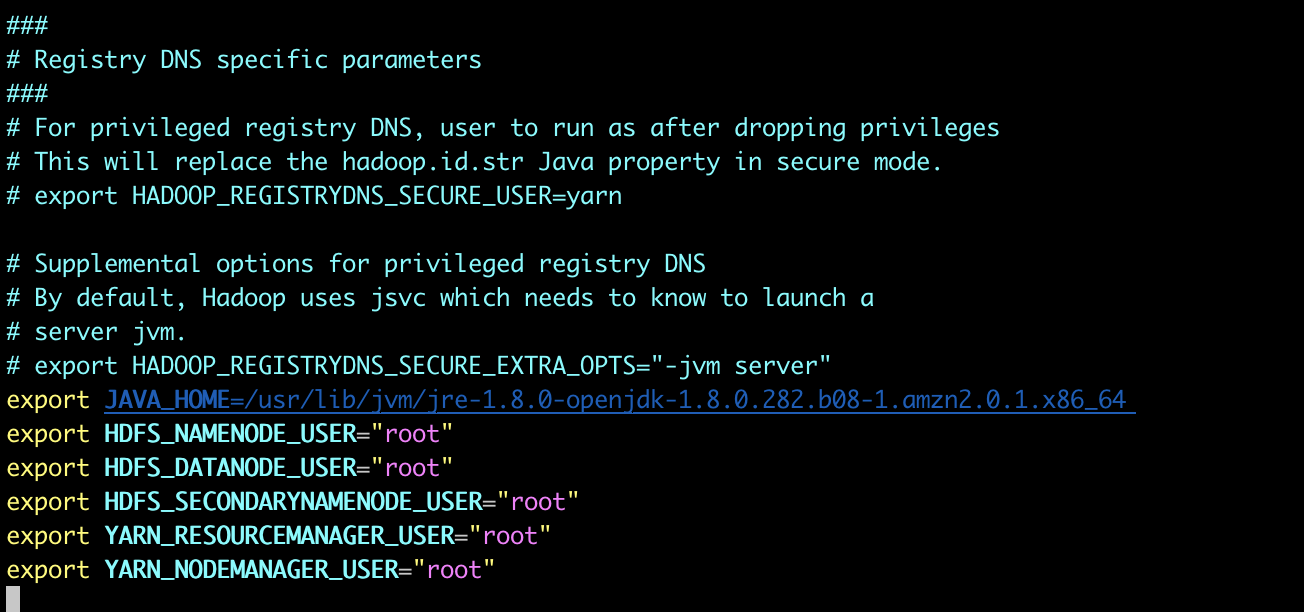
export JAVA_HOME=/usr/lib/jvm/jre-1.8.0-openjdk-1.8.0.282.b08-1.amzn2.0.1.x86_64
export HDFS_NAMENODE_USER="root"
export HDFS_DATANODE_USER="root"
export HDFS_SECONDARYNAMENODE_USER="root"
export YARN_RESOURCEMANAGER_USER="root"
export YARN_NODEMANAGER_USER="root"
3) Spark 설정파일
spark 설정파일 경로는 /usr/local/spark-3.1.1-bin-hadoop3.2/conf 입니다.
설정파일이 탬플릿 형태로 제공되기때문에, cp명령어로 파일을 복사해서 쓰시면 됩니다.
3-1) Spark-default.conf
spark-defaults.conf 파일을 복사하고 맨 아래에 세줄을 추가합니다.
[ec2-user@ip-172-31-3-64 install_dir]$ sudo cp /usr/local/spark-3.1.1-bin-hadoop3.2/conf/spark-defaults.conf.template /usr/local/spark-3.1.1-bin-hadoop3.2/conf/spark-defaults.conf
[ec2-user@ip-172-31-3-64 install_dir]$ sudo vim /usr/local/spark-3.1.1-bin-hadoop3.2/conf/spark-defaults.conf
spark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://namenode:8021/spark_enginelog
3-3) Spark-env.sh
spark-env.sh 파일을 복사하고, 아래 다섯줄을 추가합니다.
[ec2-user@ip-172-31-3-64 install_dir]$ sudo cp /usr/local/spark-3.1.1-bin-hadoop3.2/conf/spark-env.sh.template /usr/local/spark-3.1.1-bin-hadoop3.2/conf/spark-env.sh
[ec2-user@ip-172-31-3-64 install_dir]$ sudo vim /usr/local/spark-3.1.1-bin-hadoop3.2/conf/spark-env.sh
export JAVA_HOME=/usr/lib/jvm/jre-1.8.0-openjdk-1.8.0.282.b08-1.amzn2.0.1.x86_64
export SPARK_MASTER_HOST=master
export HADOOP_HOME=/usr/local/hadoop-3.3.0
export YARN_CONF_DIR=\$HADOOP_HOME/etc/hadoop
export HADOOP_CONF_DIR=\$HADOOP_HOME/etc/hadoop
여기까지 완료 되었다면 이제 다음 단계로 넘어갑니다!
5. EC2 복제하기
이제 설치된 이 EC2를 3개 더 복제하겠습니다!!!
먼저, AWS EC2 콘솔로 이동합니다.
EC2를 선택하고 작업 > 이미지 및 템플릿 > 이미지 생성을 클릭합니다.
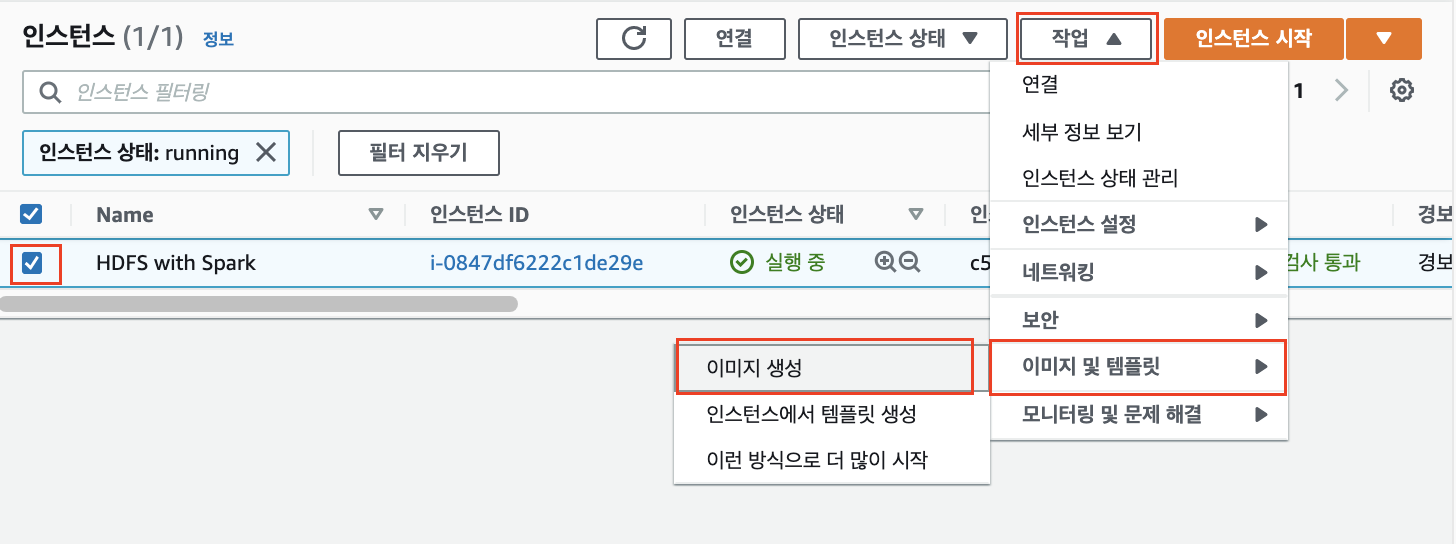
이미지 생성 페이지에서, 이미지의 이름만 작성하신 후 "이미지 생성"을 클릭합니다.
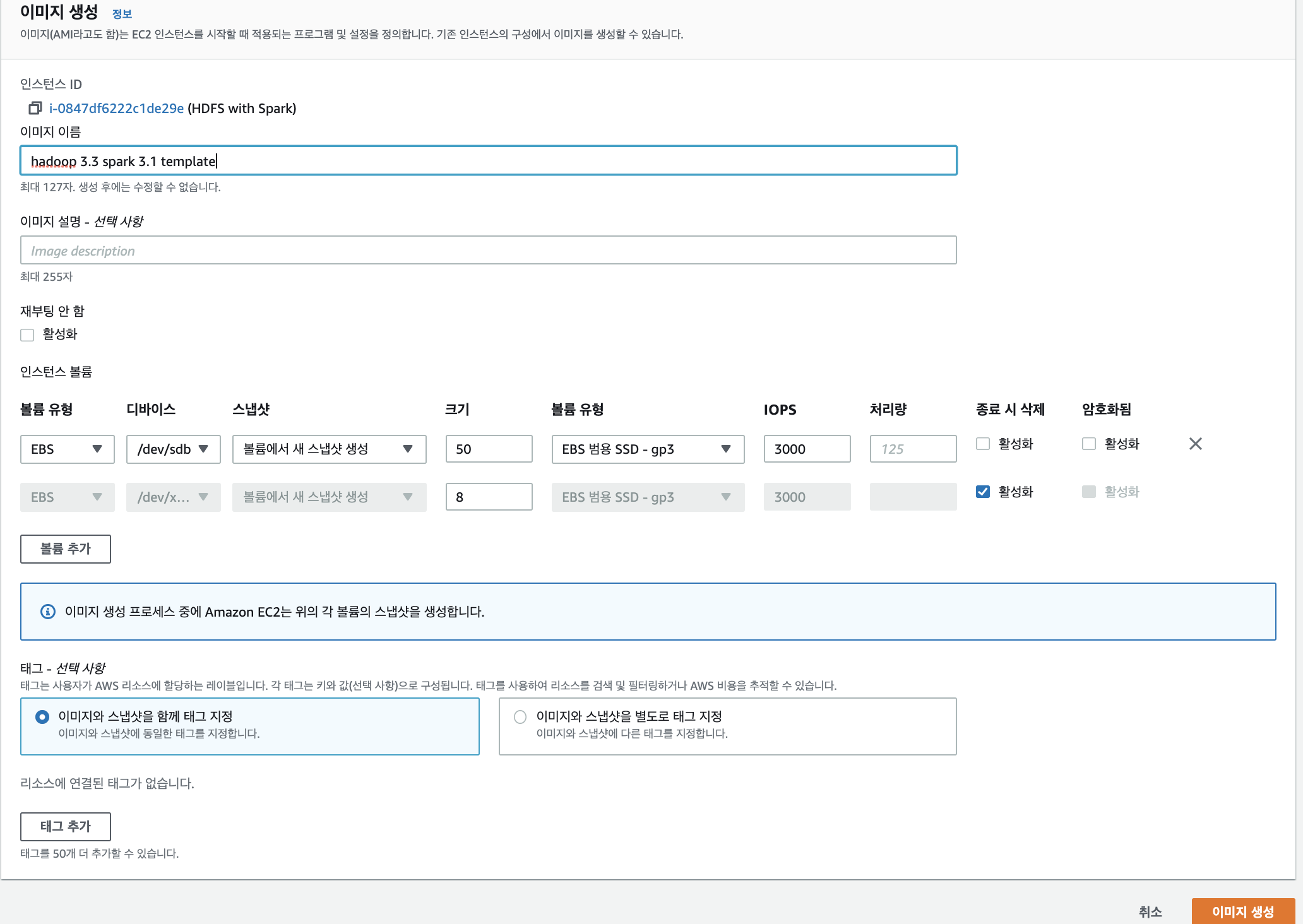
EC2콘솔, 왼쪽 네비게이션 바에서 AMI를 클릭합니다.
시간이 조금 지난 후 확인하시면 avaliable 상태로 변경된것을 볼 수있습니다.
이제, 이 이미지를 선택하고, 상단의 작업 > 시작하기를 클릭합니다.

인스턴스 유형을 선택합니다.
저는 c5.large 타입을 사용합니다. 이후 "다음:인스턴스 세부정보 구성"을 클릭합니다.
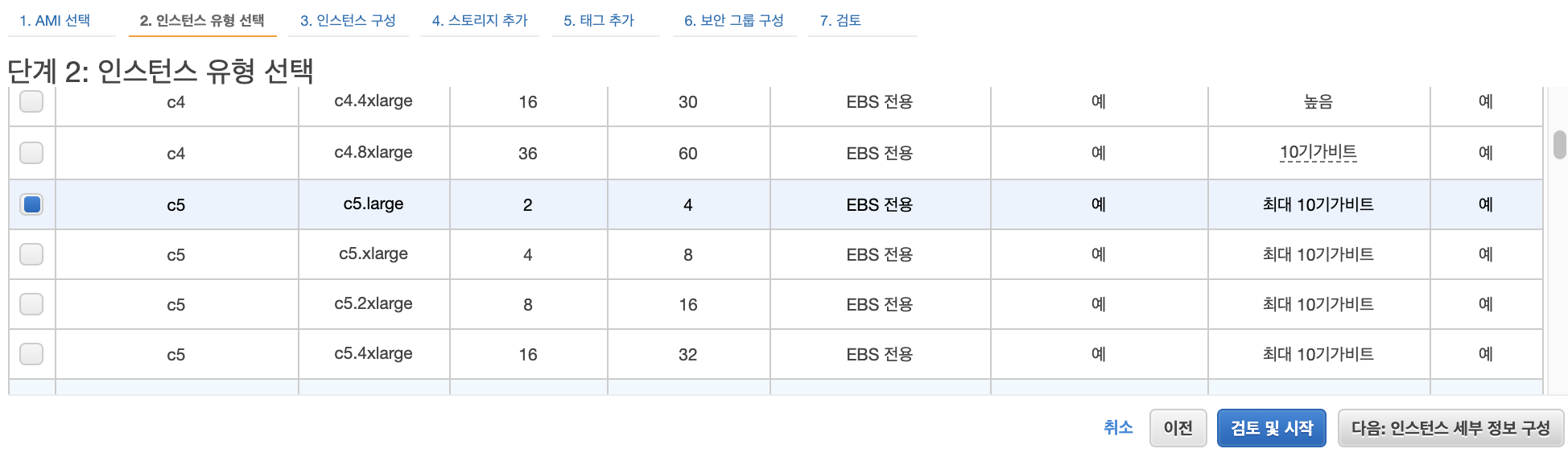
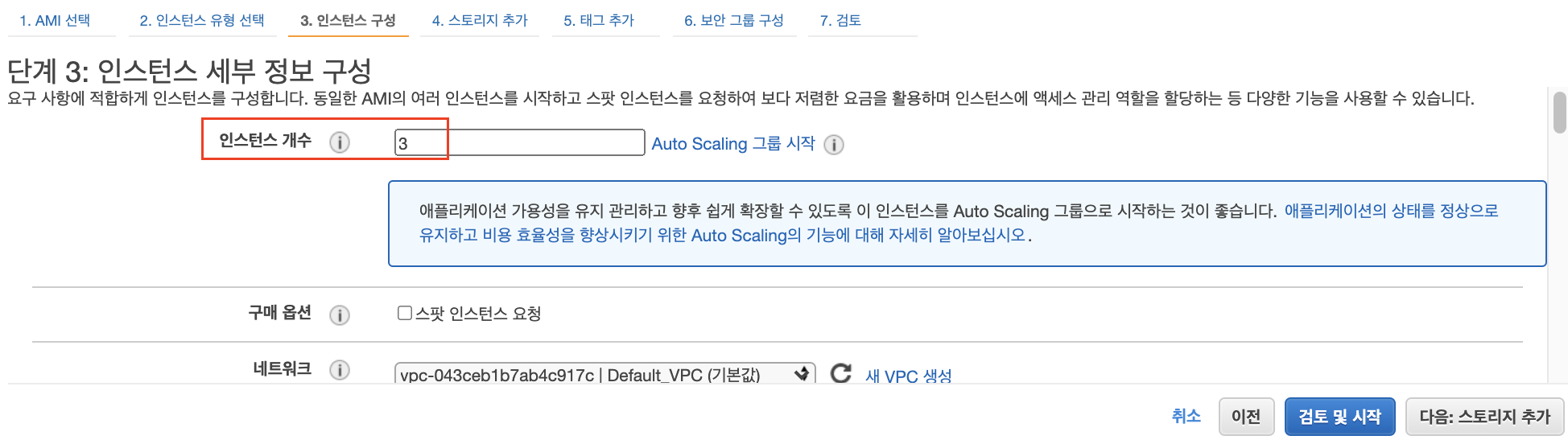
인스턴스 개수를 3으로 변경합니다.
한번에 여러개의 인스턴스를 생성할 수 있습니다. 3으로 변경 되었다면, 검토 및 시작을 클릭합니다.
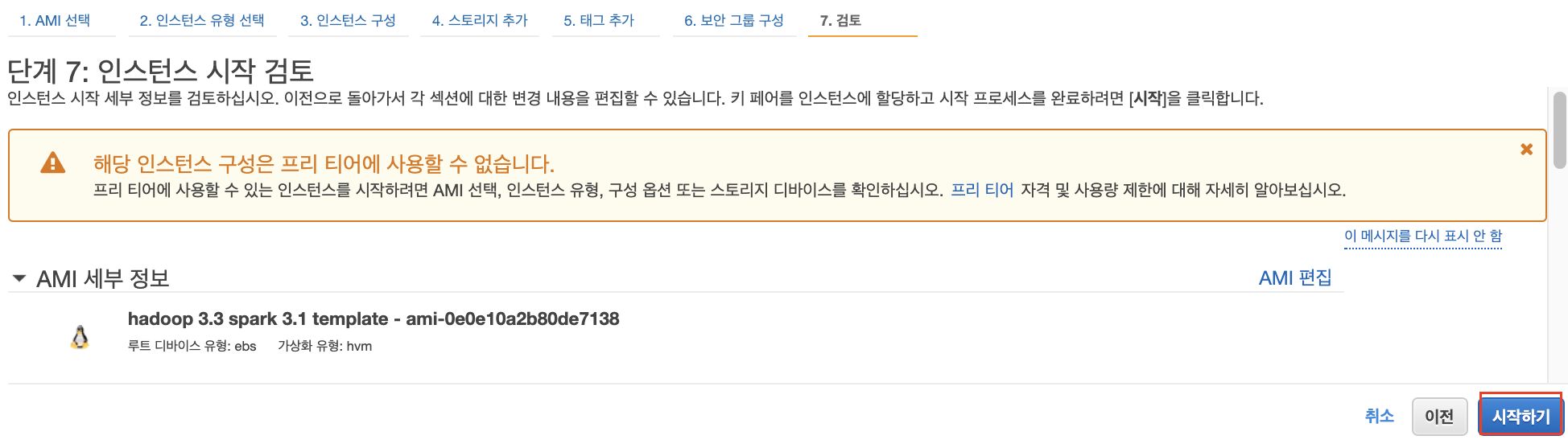
인스턴스 시작 전 검토 페이지입니다.
잘못된 부분이 있는지 한번 더 검토하고 "시작하기"를 클릭합니다.
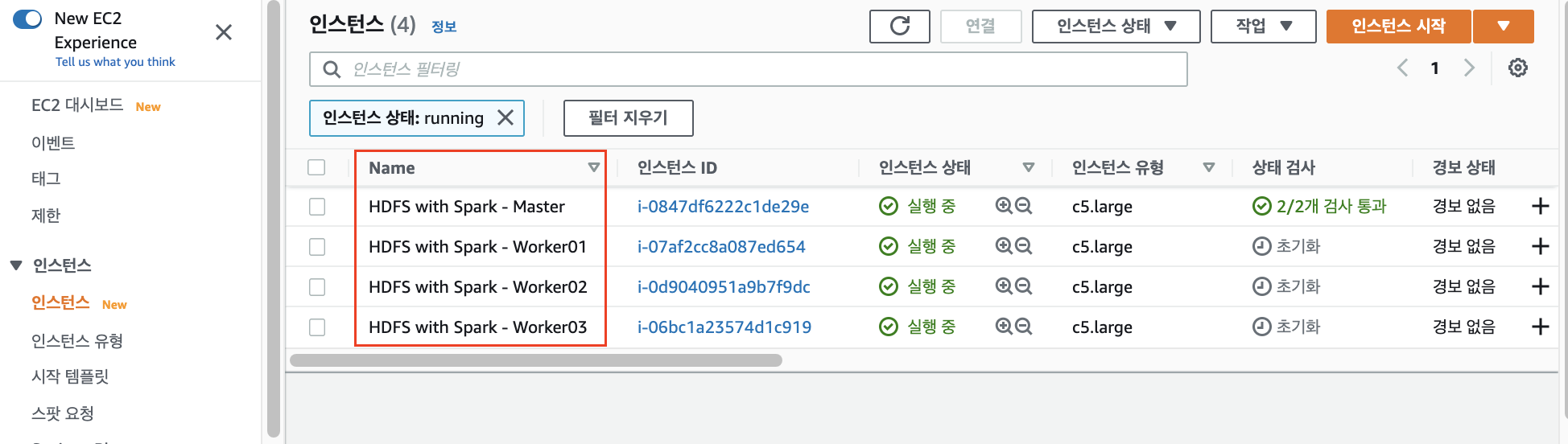
시작 후 약간의 시간이 흐르면, 아래 사진처럼 네개의 인스턴스가 운영중인 상태가 됩니다.
저는 구분하기 편하도록 Name을 변경해두었습니다.
자, 여기까지 진행 되었다면 이제 다음 포스팅으로 넘어갑니다!
나머지는 다음포스팅에서 이어집니다!! 뿅! 🤗🤗🤗